Controlling Logging in a Running JVM
Controlling logging in a running JVM can be awkward. The de facto method for administration of a running JVM is Java Management Extensions, but JMX has been awkward to use because it's traditionally had a focus on static interfaces and annotations, and was confusing at best to implement.
Despite that, it's entirely possible to put together a grab bag of attributes and operations from any place you like and have it exposed and registered to the system, using the DynamicBean API. Likewise, you don't need to worry about how to expose that information using the MXBean API together with the OpenData mapping, which restricts data types to a "JSON like" set of String, Number, java.util.Date and CompositeData and TabularData, which fulfill roughly the position of JSON objects and arrays.
I put together a fluent builder API called jmxbuilder that lets you create something useful in a single statement:
public class UserExample {
private static final MBeanServer mBeanServer = ManagementFactory.getPlatformMBeanServer();
static final CompositeDataWriter<Address> addressWriter = CompositeDataWriter.<Address>builder()
.withTypeName("address")
.withTypeDescription("Address")
.withSimpleAttribute("street1", "Street 1", Address::getStreet1)
.withSimpleAttribute("city", "City", Address::getCity)
.withSimpleAttribute("state", "State", Address::getState)
.build();
public static void registerUser() throws Exception {
Address address = new Address("street1", "city", "state");
final User user = new User("name", 12, address);
final DynamicMBean userBean = DynamicBean.builder()
.withSimpleAttribute(String.class, "name", user::getName, user::setName)
.withSimpleAttribute(Integer.TYPE, "age", user::getAge, user::setAge)
.withCompositeAttribute("address", user::getAddress, addressWriter)
.withOperation("ping", user::ping)
.build();
ObjectName objectName = new ObjectName("com.tersesystems.jmxbuilder:type=UserBean,name=User");
mBeanServer.registerMBean(userBean, objectName);
}
}
This makes logging and debugging much easier, because you add functionality to all your components by putting together a builder with some components. You can then go in and change logging on an individual component.
We can demo this using Play Framework, by adding logging to a base controller class. The code is available at https://github.com/wsargent/play-scala-with-jmx.
First, we set up SBT so that it's running Jolokia and has the client and jmxbuilder available:
lazy val root = (project in file("."))
.enablePlugins(PlayScala, JavaAgent)
.settings(
name := """play-scala-with-jmx""",
organization := "com.example",
version := "1.0-SNAPSHOT",
scalaVersion := "2.13.1",
javaAgents += JavaAgent( "org.jolokia" % "jolokia-agent-jvm" % "2.0.0-M3" classifier "agent", arguments = "host=0.0.0.0,port=8778"),
resolvers += Resolver.bintrayRepo("tersesystems", "maven"),
libraryDependencies ++= Seq(
guice,
"com.tersesystems.jmxbuilder" % "jmxbuilder" % "0.0.2",
"org.jolokia" % "jolokia-client-java" % "2.0.0-M3",
"org.scalatestplus.play" %% "scalatestplus-play" % "5.0.0" % Test
),
scalacOptions ++= Seq(
"-feature",
"-deprecation",
"-Xfatal-warnings"
),
)
Then we can define a LoggingComponent with getLoggingLevel and setLoggingLevel:
trait LoggingComponent {
def setLoggingLevel(level: String): Unit
def getLoggingLevel: String
}
trait LogbackLoggingComponent extends LoggingComponent {
protected def logbackLogger: Logger
override def getLoggingLevel: String = {
val logger = logbackLogger.asInstanceOf[classic.Logger]
logger.getEffectiveLevel.toString
}
override def setLoggingLevel(level: String): Unit = {
new ChangeLogLevel().changeLogLevel(logbackLogger, level)
}
}
Then we set up a DynamicBean.builder with some level values, using jmxbuilder:
object LoggingComponent {
def jmxBuilder(lc: LoggingComponent): DynamicBean.Builder = {
val levelsSet = new java.util.HashSet[String]()
java.util.Collections.addAll(levelsSet, "OFF", "ERROR", "WARN", "INFO", "DEBUG", "TRACE")
val descriptor = DescriptorSupport.builder()
.withDisplayName("level")
.withLegalValues(levelsSet)
.build()
val attributeInfo = AttributeInfo.builder(classOf[String])
.withName("loggingLevel")
.withBeanProperty(lc, "loggingLevel")
.withDescriptor(descriptor)
.build()
DynamicBean.builder.withAttribute(attributeInfo)
}
}
We set up a JMXServer so that we can unregister the bean when the Play application is unloaded. We need this because in development mode, Play will close and recreate the Application inside the same JVM with a different classloader, so we need to clean up any references.
@Singleton
class JMXServer @Inject()(lifecycle: ApplicationLifecycle) {
def registerBean(objectName: ObjectName, bean: DynamicBean): Unit = {
import java.lang.management.ManagementFactory
val mbs = ManagementFactory.getPlatformMBeanServer
mbs.registerMBean(bean, objectName)
lifecycle.addStopHook { () =>
mbs.unregisterMBean(objectName)
Future.successful(())
}
}
}
And then finally we set up a registerWithJMX method, and expose a protected decorateBean method so that different controllers can add extra attributes and operations to the dynamic bean.
@Singleton
class MyAbstractController @Inject()(mcc: MyControllerComponents)
extends AbstractController(mcc)
with Logging with LogbackLoggingComponent with RegistrationComponent {
override protected def logbackLogger: Logger = logger.logger
registerWithJMX(new ObjectName(s"play:type=Controller,name=${getClass.getName}"), mcc.jmxServer)
}
trait RegistrationComponent {
self: LoggingComponent =>
protected def decorateBean(builder: DynamicBean.Builder): DynamicBean.Builder = builder
protected def registerWithJMX(objectName: ObjectName, jmxServer: JMXServer): Unit = {
val bean: DynamicBean = decorateBean(LoggingComponent.jmxBuilder(this)).build
jmxServer.registerBean(objectName, bean)
}
}
For rendering logging events, we're going to pull information from Logback, expose it as a TabularData attribute, and then query it using the Jolokia client.
First, we define the LoggingEventsBean:
@Singleton
class LoggingEventsBean @Inject()(loggerContext: LoggerContext, jmxServer: JMXServer) {
class CyclicAppenderIterator[E](appender: CyclicBufferAppender[E]) extends java.util.Iterator[E]() {
private var index = 0
override def hasNext: Boolean = index < appender.getLength
override def next(): E = {
val event = appender.get(index)
if (event == null) {
throw new NoSuchElementException("no event")
} else {
index = index + 1
}
event
}
}
def findCyclicAppender: Option[CyclicBufferAppender[ILoggingEvent]] = {
val rootLogger: Logger = loggerContext.getLogger(org.slf4j.Logger.ROOT_LOGGER_NAME)
rootLogger.iteratorForAppenders().asScala.collectFirst {
case cyclicBuffer: CyclicBufferAppender[ILoggingEvent] =>
cyclicBuffer
}
}
def iterator: util.Iterator[ILoggingEvent] = findCyclicAppender.map(new CyclicAppenderIterator(_)).getOrElse {
java.util.Collections.emptyIterator()
}
val bean: DynamicBean = LoggingEventsBean(iterator)
jmxServer.registerBean(new ObjectName(s"play:type=CyclicBuffer,name=${getClass.getName}"), bean)
}
Then, we define the dynamic bean mapping:
object LoggingEventsBean {
private val compositeEvents = CompositeDataWriter.builder(classOf[ILoggingEvent])
.withTypeName("loggingEvent")
.withTypeDescription("Logging Event")
.withSimpleAttribute("timestamp", "Message", e => new java.util.Date(e.getTimeStamp))
.withSimpleAttribute("name", "name", _.getLoggerName)
.withSimpleAttribute("level", "Level", _.getLevel.toString)
.withSimpleAttribute("message", "Message", _.getFormattedMessage)
.build();
private val tabularEventsWriter: TabularDataWriter[ILoggingEvent] = TabularDataWriter.builder(classOf[ILoggingEvent])
.withTypeName("events")
.withTypeDescription("Logging Events")
.withIndexName("timestamp")
.withCompositeDataWriter(compositeEvents).build
def apply(iter: => java.util.Iterator[ILoggingEvent]): DynamicBean = {
DynamicBean.builder().withTabularAttribute("events", () => new java.lang.Iterable[ILoggingEvent]() {
override def iterator: java.util.Iterator[ILoggingEvent] = iter
}, tabularEventsWriter).build()
}
}
and then finally we have a query service talk to Jolokia and pull on the exposed tabular data to display it locally:
@Singleton
class JolokiaQueryService {
def loggingEvents: Seq[LoggingRow] = {
val client = new J4pClient("http://localhost:8778/jolokia")
val request = new J4pReadRequest("play:type=CyclicBuffer,name=logging.LoggingEventsBean","events")
val response: J4pReadResponse = client.execute(request)
val result: JSONObject = response.getValue()
val unsortedList = Json.parse(result.toJSONString).as[Map[String, JsValue]].toIndexedSeq
unsortedList.sortBy { case (isoDate, _) =>
Instant.from(DateTimeFormatter.ISO_OFFSET_DATE_TIME.parse(isoDate))
}.map { case (_, v) => v.as[LoggingRow] }
}
}
After that, we just have to extend as per normal and all the functionality is hidden under the hood:
@Singleton
class HomeController @Inject()(jolokiaQueryService: JolokiaQueryService, cc: MyControllerComponents) extends MyAbstractController(cc) {
def index() = Action { implicit request: Request[AnyContent] =>
logger.debug("rendering index: ")
val loggingEvents = jolokiaQueryService.loggingEvents
Ok(views.html.index(loggingEvents))
}
}
and then we can see the cyclic buffer when we go to http://localhost:9000, and we get this when we bring up Hawt in console:
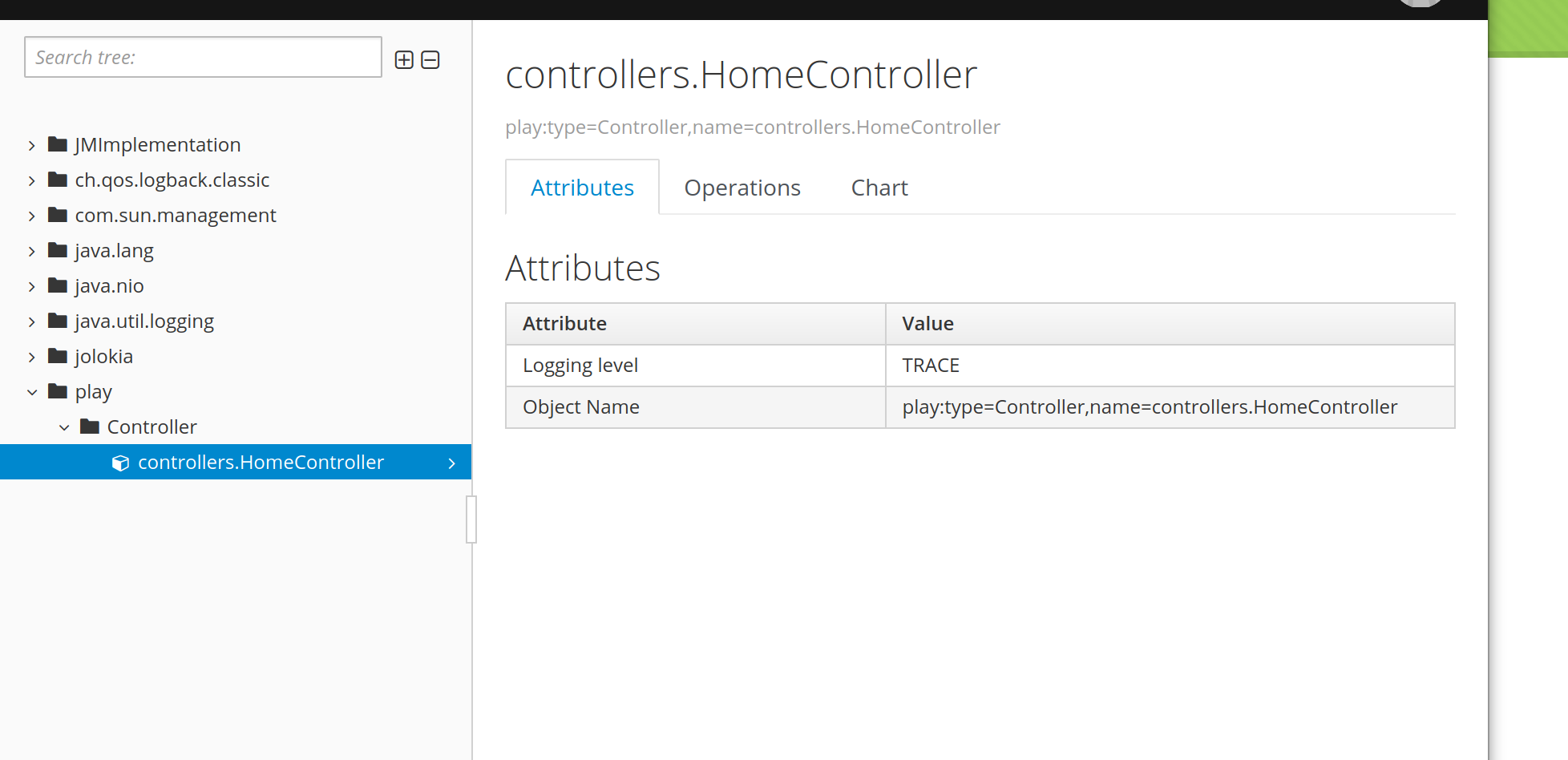
I've also been poking at automatic registration of components with JMX. There's an old Sun project called Dynamic Management Kit which was open sourced and left on the wayside by Oracle. I found the documentation, tracked down an example of a virtual mbean interceptor, and broke it out into jmxmvc. This lets me do things like automatically register Akka actors in JMX:
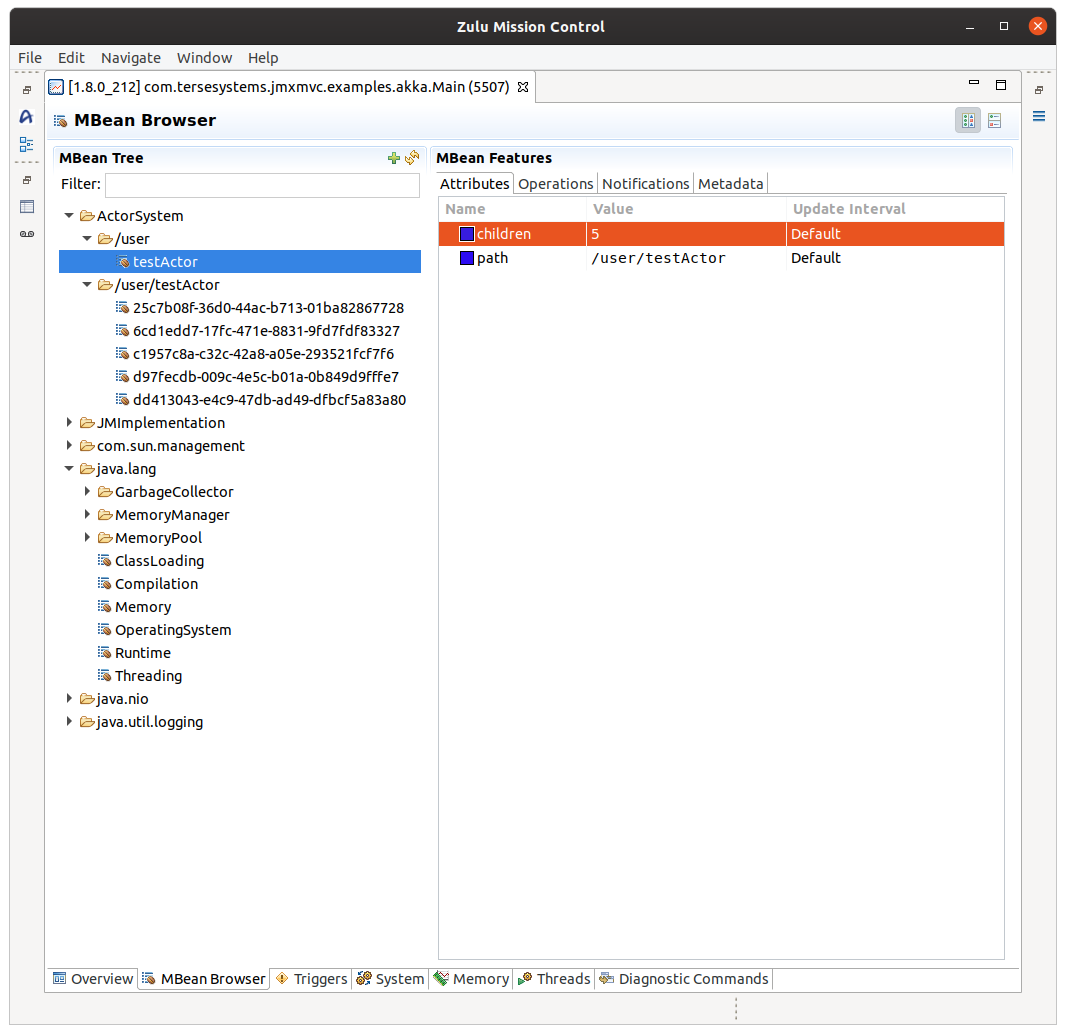
I don't claim to say that this is useful, but it's fun, and I enjoy bricolage, so why not.