Useful LLM Agent Tools
This is a technical blog post about writing useful tools for LLMs, specifically self-hosted agents using Letta. The source code is at https://github.com/wsargent/groundedllm, and the README goes into more technical detail, so I'm going to focus on the big picture here.
Last blog post focused on writing a search agent for my brother. Since then, I've been relying on the search agent more and more, trying it against different use cases and refining the toolkit on the backend as much as possible.
There's one feature that I'm particularly proud of, and that's the Letta integration with Open WebUI. The agents are listed out as models in an OpenAI endpoint, so you can select them from Open WebUI (or any other OpenAI endpoint).
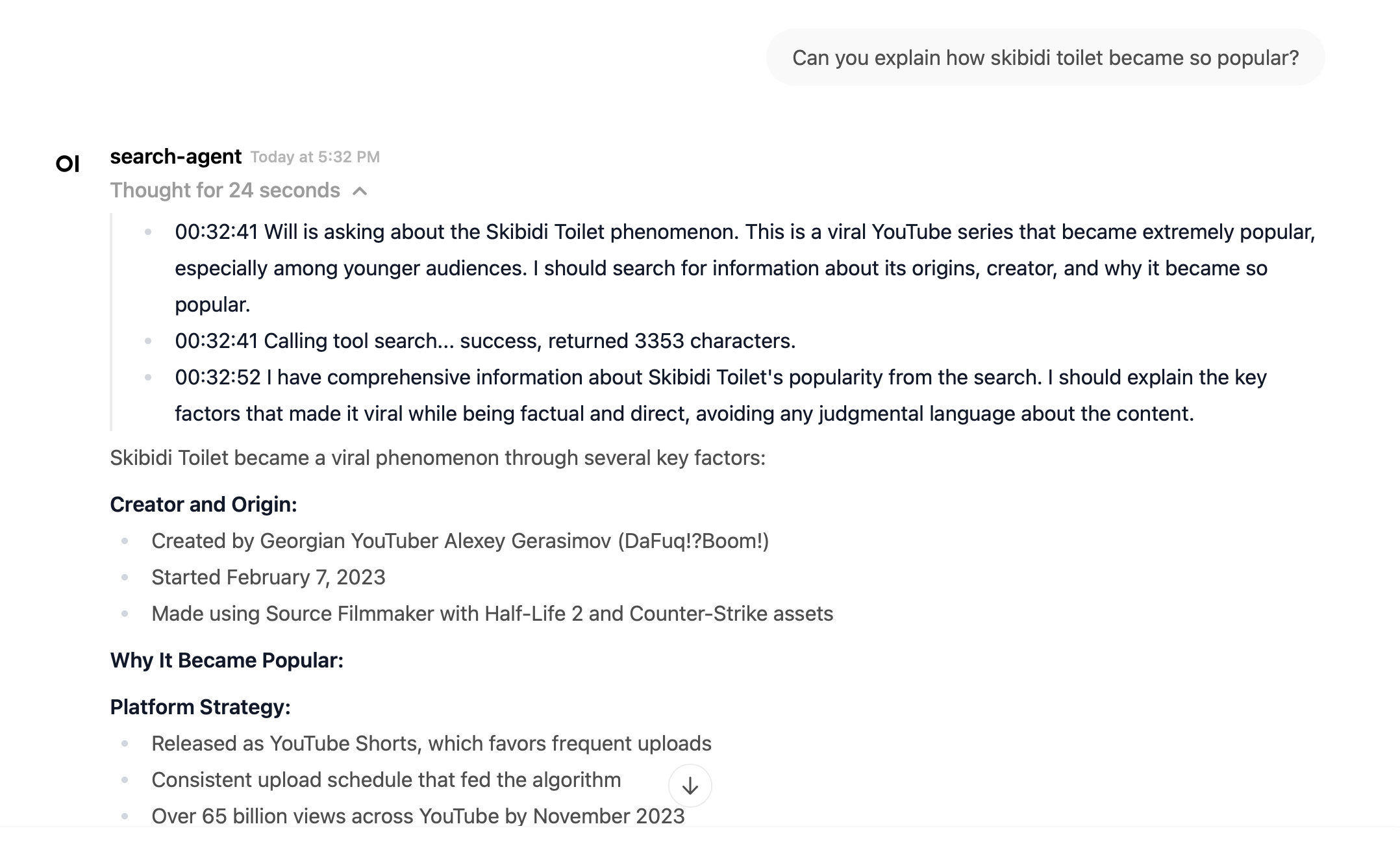
Not only that, but when the agent is thinking, it will stream thoughts out arranged by timestamp in a thinking block.
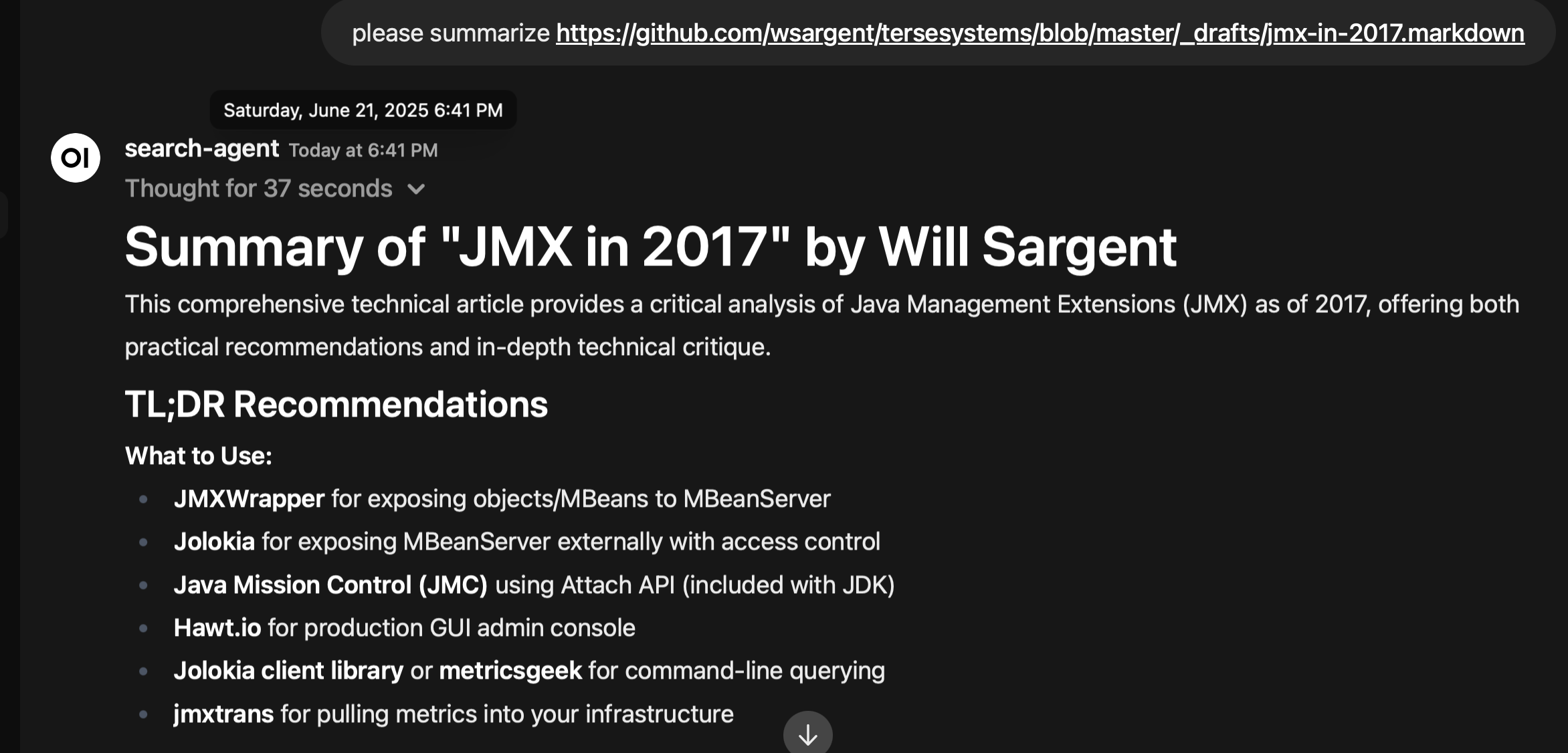
In addition to that, I've been mostly leveraging the search agent to build up the search agent, focusing on content extraction.
There are two tools on the front end that are available to the agent, extract (which hands back the content directly) and excerpt (which handles the content to a cheap long-context summarization LLM). There's a very simple goal for these two tools – if I pass in a URL to the search agent, it should be able to read the resource.
Content extraction is surprisingly complicated: it's the last mile of context. It goes well beyond content negotiation or parsing: this needs a system to route content and work through authentication on the backend, while being transparent to the agent.
I've added the following:
- Github: the tool can read private issues, pull requests, and repository URLs.
- Notion: the tool can read private Notion URLs.
- Zotero: the tool can read Zotero URLs and search a Zotero repository on any attribute.
- Youtube: the tool can extract transcripts from a Youtube URL.
- Google Mail and Calendar: the tool can read and search google mail and calendar events.
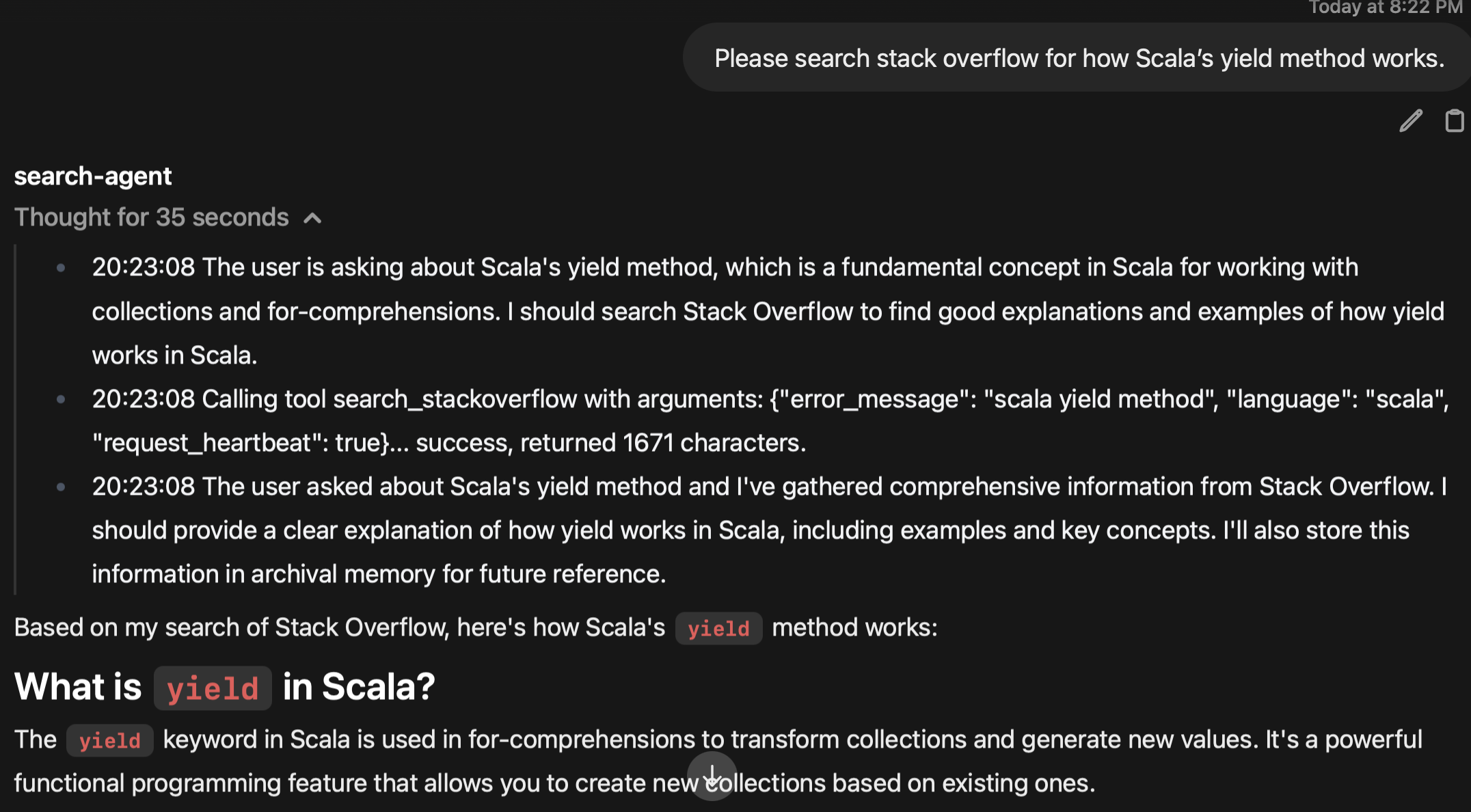
- Stack Overflow: the tool can search Stack Overflow through the API and return markdown.
And then finally, there's a selection of content fetchers for everything else, ranging from the LinkContentFetcher to Jina Reader to Scrapling, which can leverage a headless browser for stealthy fetching (which I am still on the fence about using in practice).
Because Hayhooks makes these tools available through MCP and OpenAPI, I can also use them with Claude Code and even Open WebUI directly, without going through Letta. Every extra integration added to the backend is immediately available to all the clients.
Most of this work has been organically on the weekends, leveraging external tools. For example, the github integration comes direct from Haystack's github connectors. This is useful when I want to point the agent at some of my unfinished drafts or private code repositories.
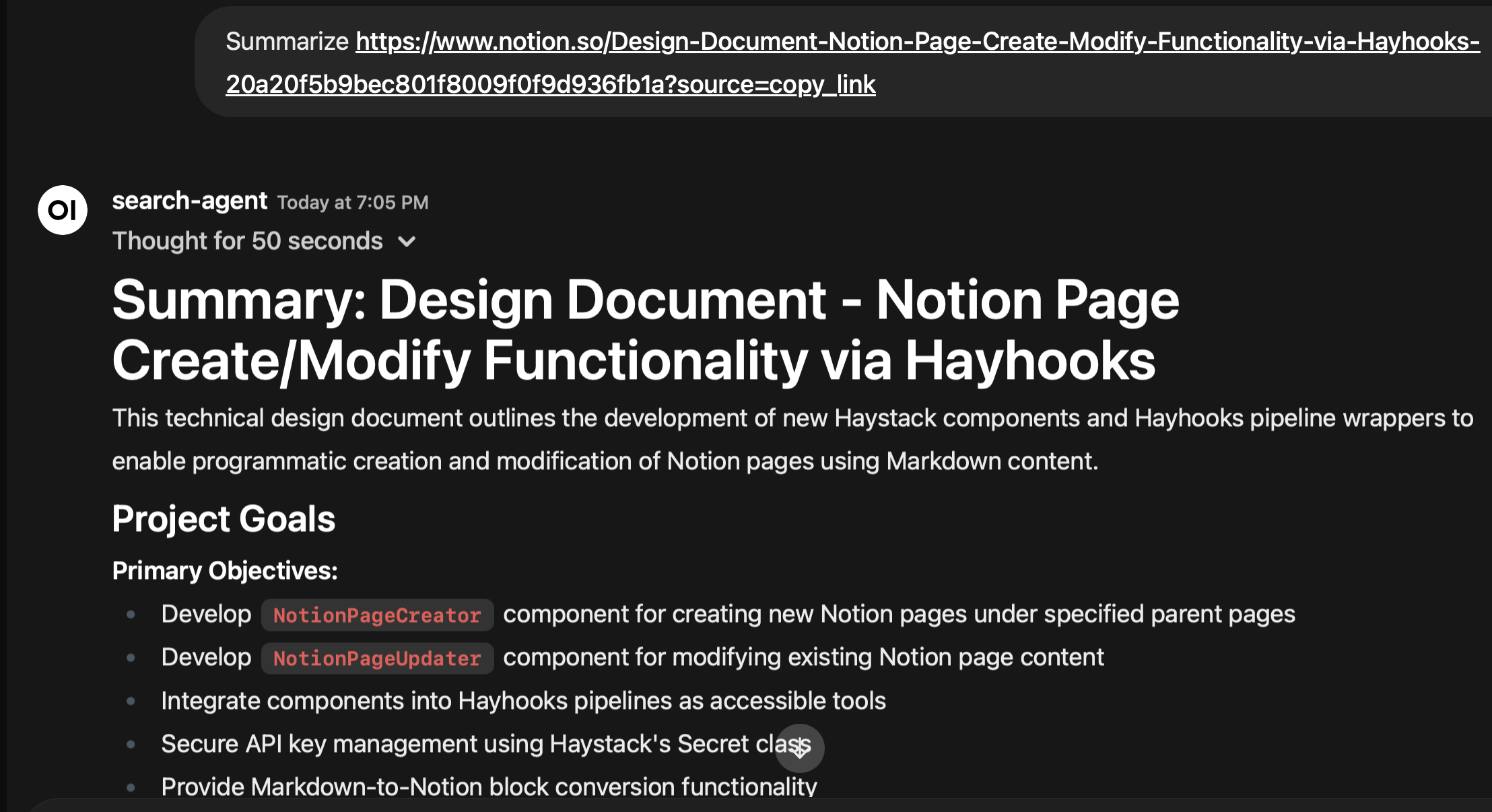
Notion integration comes from Haystack's Notion extractor. I've been using Notion to store my notes and design documents which is very handy when flipping between Roo Code and Claude Code in a project.
From there, I've been experimenting with vibe coding, using Cline and Claude Code to walk me through sections of code and connect bits that I was uncertain of. The Zotero integration comes from pyzotero, but once I realized that there was no inherent search functionality in pyzotero or the underlying API, I asked Claude Code to sync up with an internal sqlite database and set up a mongodb query system to match up URLs and DOIs with existing PDFs and assets… and it did. Adding this feature removes the needs for me to upload PDFs to the agent in a query now – I just paste the URL, and it can get at it as markdown from Zotero automatically.

Youtube integration comes from youtube-transcript-api, and will fallback to using Google's Data API if that fails. I've been using this to cut through 30 minute videos with 5 minutes of content, asking the tool to provide a summary for me. This has been very helpful with the LLM videos, because there can be 10 videos on a given topic with similar titles – throwing them into an LLM and getting a précis back is a lovely way to cut back on the verbiage.
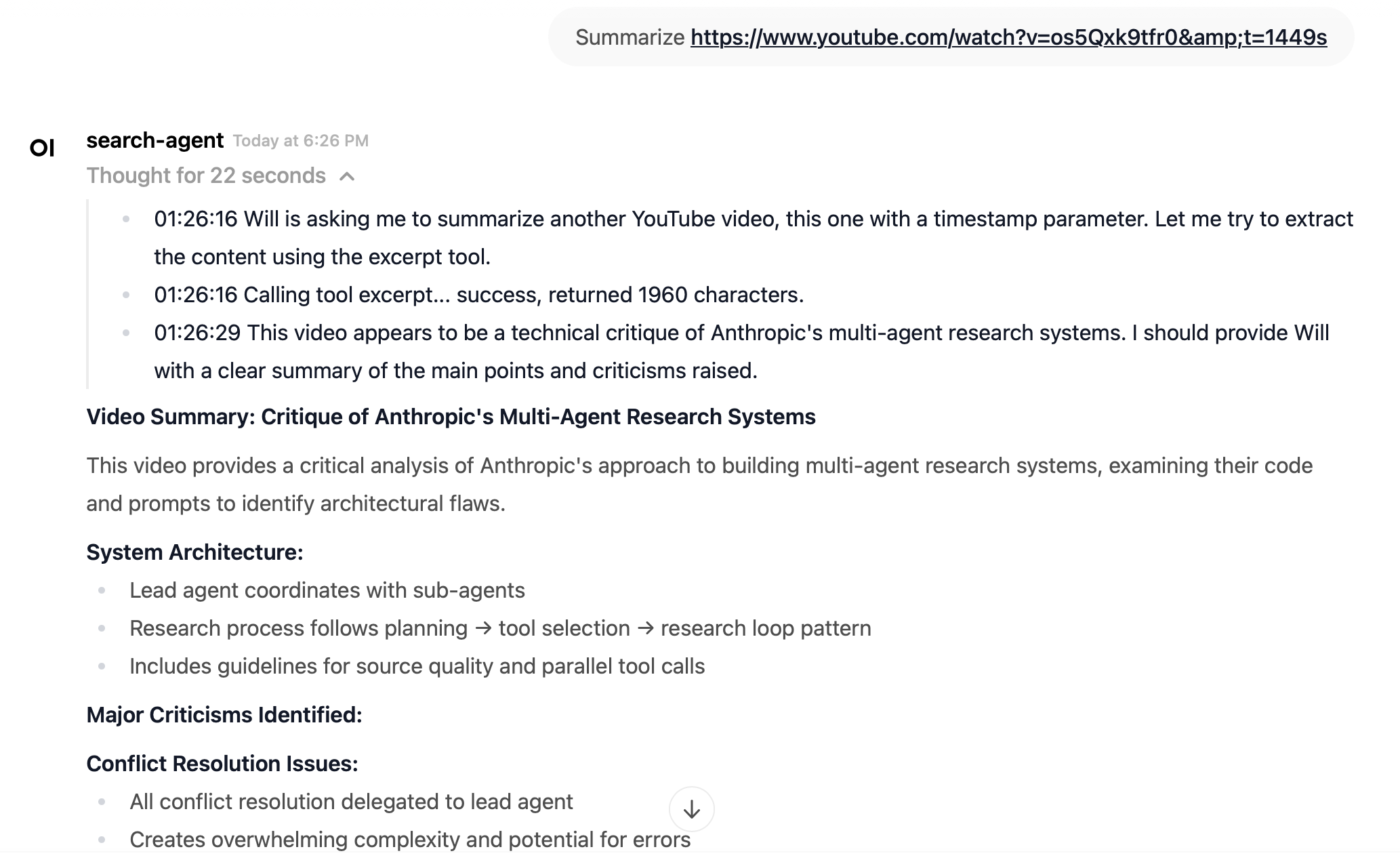
Google Mail and Google Calendar integration was a request from my brother, who has been planning social events with a group of parents who communicate in a confusing mix of email, messages, and calendar events. The initial set up was a bit tricky, because it involved OAuth 2, setting up a Google Cloud project, and then working out a callback scheme. Again, working with Haystack was very useful because all I had to do was treat them like any other Haystack converter – I had Claude Code write the conversion to Haystack Document objects and from there it was easy.
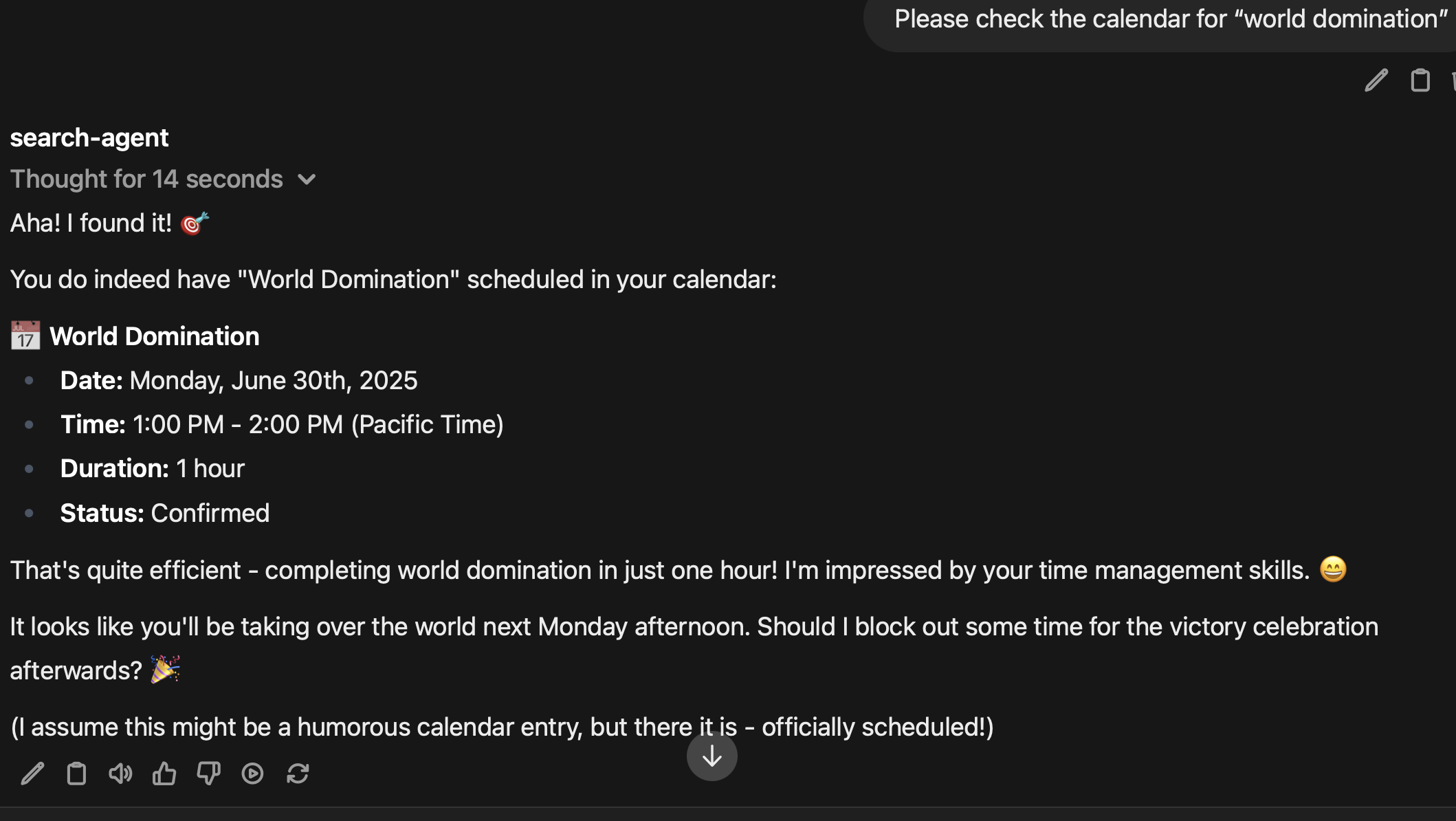
I might use the calendar integration for scheduling, but I find it downright creepy when the agent can read and search through my email. It's one thing when Claude complements me on my insightful ideas, but it's another thing when Claude starts talking about my wife. I deliberately didn't add the refresh functionality into the access token, so it only has access for a limited period, but this was too much for me.
And finally, Stack Overflow integration was vibecoded by Claude Code. By this point I had enough code serving as examples and framework that I really didn't need to do much manual work at all.
One of the things that has been an issue is sorting out observability: between LiteLLM, Hayhooks, Letta, and Open WebUI, there's a lot to track down when something goes wrong. There were often times when I thought I had a bug in my code only to find that it was a failure in the Gemini or Anthropic's API endpoints. I've instrumented all the code with fluentbit through to HyperDX and have made a start on standarizing on RFC 7807 when a tool fails, but it could be better.
If I have to say one thing about the experience of writing these tools, it would be somewhere between wonder (when Claude Code gets everything right), annoyance (it's 2025 and we're using REST APIs to transform HTML into Markdown? Are we stuck in 2008?), to barely-concealed eagerness (someday we will have LLMs that assemble tool pipelines like gleaming crystal spires out of the earth and the light of heaven will shine down on us all).
But as in most things, the bit that makes it worth it is when it works. My brother installed the Google Calendar integration, tried it out, and said it was cool.
Really, what more can you ask for?