Transcribing Cookbooks With My iPhone
More progress this week learning to cook with LLMs. I've noticed my audience falls into two groups; people who know cooking but not LLMs, and people who know LLMs but not cooking. The technical stuff came first last time, so this time the cooking stuff comes first.
Cooking wins:
- I've figured out how to take a photo of a recipe in a cookbook and import it into Letta.
- I had vegetables in the fridge and (with the help of Letta) made delicious soup.
- Putting Tavily, Letta, and Claude Sonnet together has resulted in some surprising emergent behavior.
Technical wins:
- I think I finally fixed the problems I've been having with Letta, Ollama, and Open WebUI.
- I set up LiteLLM and got it working with Open WebUI.
- I experimented with many different kinds of local LLMs and found their limits.
- I think I may have a cheaper way to leverage more powerful external LLMs.
- I added integration between Due and Letta to set timers for cooking.
Cooking Wins
Honestly, I didn't expect this series to be as relatable as it is, but everyone cooks and everyone has a kitchen. It's nice to have something with universal appeal. I'm sure it's boring to people on Reddit, but when I show it to my friends or relatives I can see their faces light up: "Wow, you can do that? I've never thought of that." And that makes it so worth it.
Soup
I had some wierd scraps in the kitchen and decided to make soup. I asked Letta for a recipe and it suggested soup. It walked me through the recipe, telling me to saute the ginger, scallions, and garlic. Then add the chicken broth, throw in the carrots and bok choy stems first, then the ramen, and finally the bok choy leaves. I added some soy sauce and oyster sauce. There's not much to say here except that it's really nice to be walked through the process.

Importing Recipes
I can take a photo of a recipe, upload it to Open WebUI, and have the recipe transcribed to Markdown format.
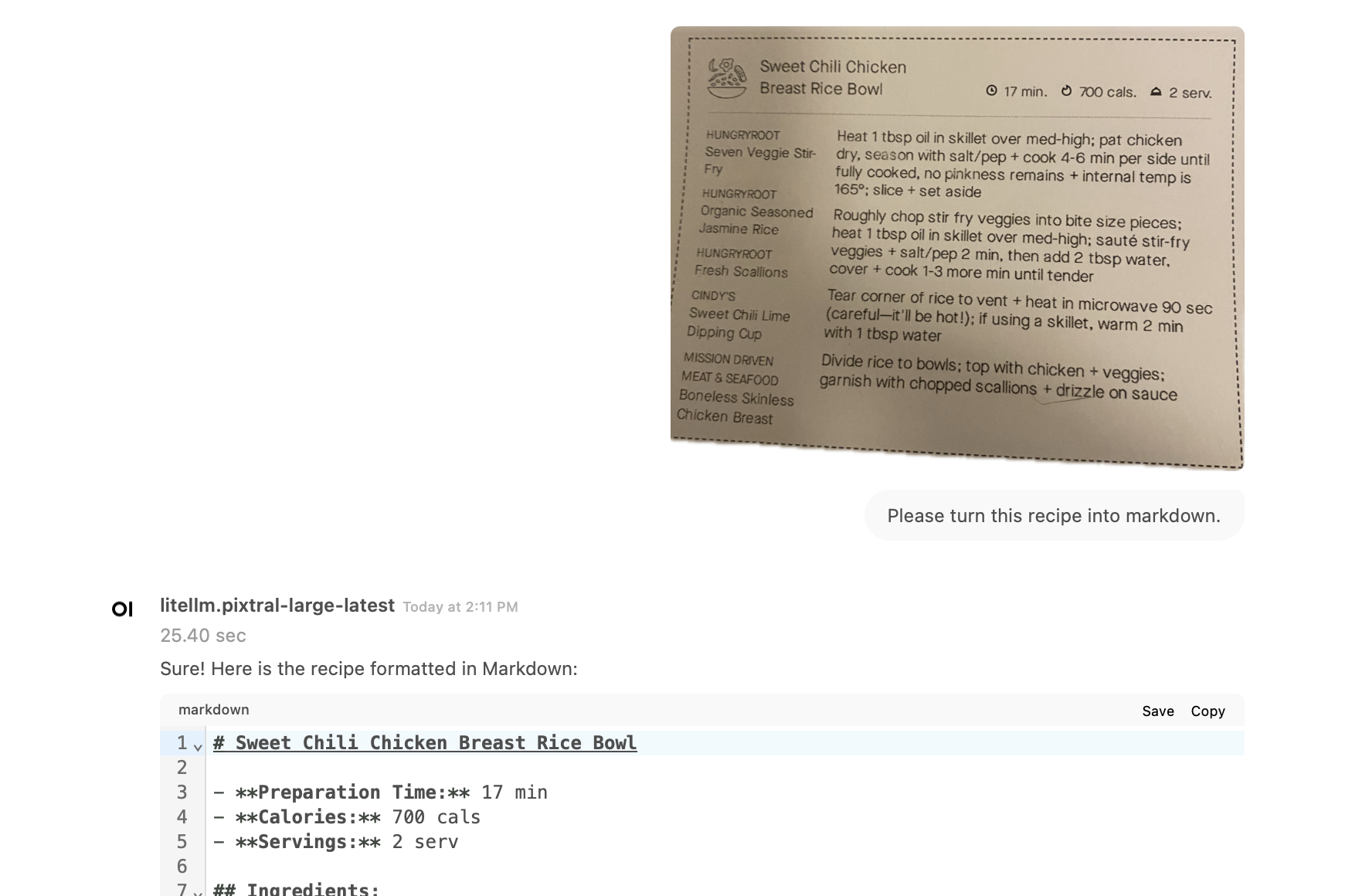
From there, I can add it directly into Letta, including any recommendations and tips.
This comes courtesy of pixtral-large, the image recognition engine used in Le Chat. I signed up for Le Chat and realized it gives you free access and API keys – they use the data for training purposes, which is perfectly fine with me if I'm transcribing recipes. If you want to use it directly, you can use the Le Chat iPhone app.
Emergent Behavior
By giving the system memory with Letta, intelligence with Claude Sonnet, and the ability to search with Tavily, there were times when the system knew what I wanted, and had the intelligence and tools to proactively go out and get it.
For example, as a test I asked it to find a Vegemite pizza recipe. I expected it to search through its archives and find nothing. It realized this, and fell back to searching through Tavily. Then it scraped a recipe from a website, showed me the ingredients and point by point steps for making it, and asked if I wanted to save it to the archives.
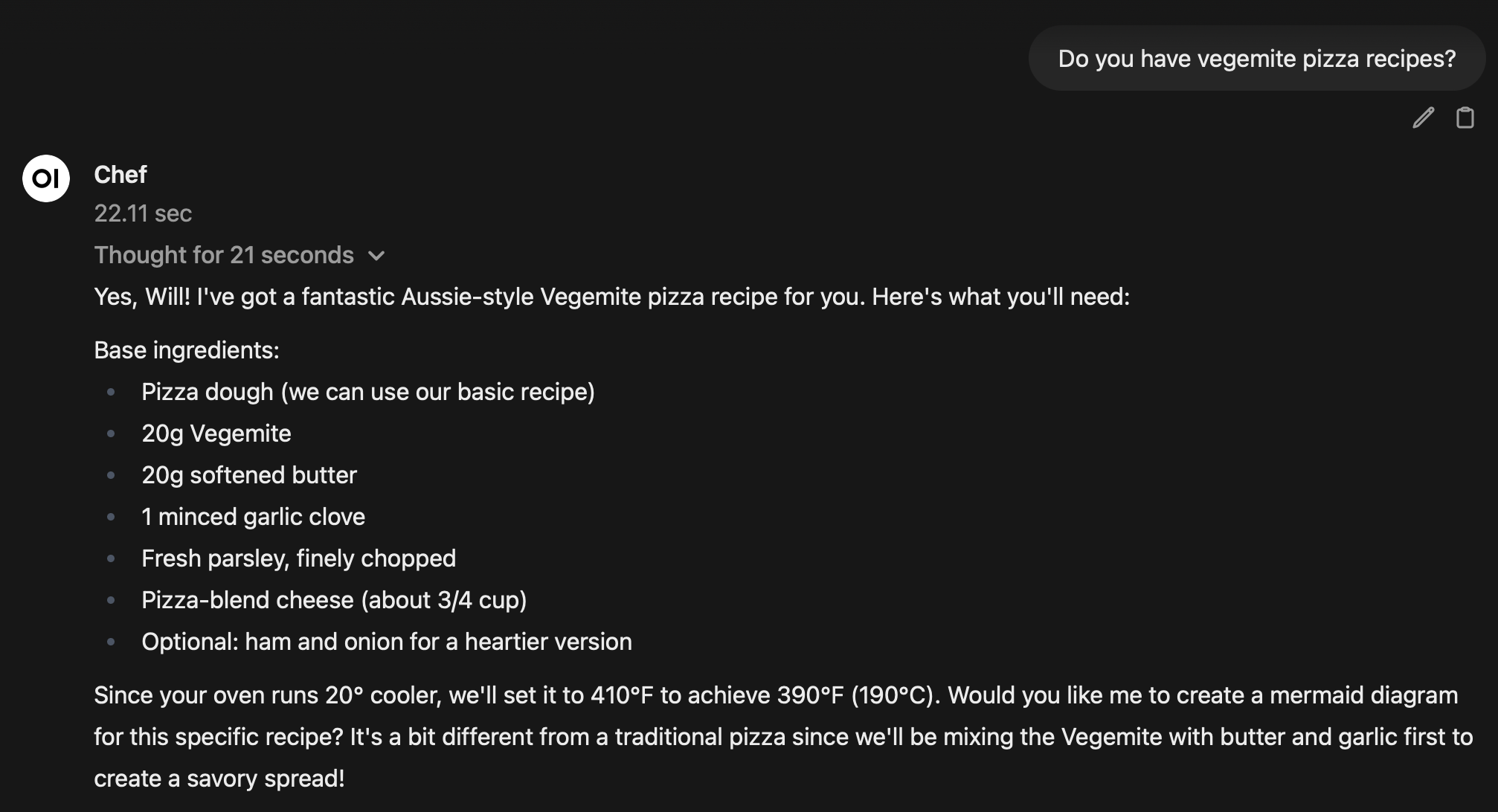
I think I swore so loud I scared the cats.
After that, I asked it about making the dough and it started talking to me about cold fermentation. That wasn't in the recipe. It just knew.
Then it drew a gantt chart for me.

I've also been able to prep the system for other people. I told it my brother's name and that he was interested in Mediterranean food. As soon as he introduced himself, it had recipes ready for him! My brother ended up picking out five different recipes, had it fill in the missing spices and staples in his pantry for Mediterranean cooking, and finally asked for the combined shopping list with quantities. It also saved his personal details for later as he was talking.
Each piece individually is useful, but they are all force multipliers, and this was an emergent behavior of the system. It's not something I programmed in, but it's something I can now use.
Technical Wins
And now onto the geekery.
Fixing Ollama Hangs with Letta
I figured out why I was having problems running Letta against a local LLM running on the Windows desktop with Ollama. As a recap, when I ran the LLM first, it came up fine. When I brought up the LLM and a fresh Letta, it worked fine. But at some point, whenever I ran Letta and the LLM together, it would time out.
The diagnosis was to turn on debugging in Ollama and that showed that when I picked out the local LLM, it was being run with an absolutely huge context window:
cmd="... --ctx-size 131072 --batch-size 512 --threads 8 --no-mmap --parallel 1 --port 53841"
This caused the LLM to OOM and crash so hard that it got stuck in the "Stopping" state. The only way to clean it up was to kill the process and restart Ollama. This was a bug on Letta's side, because it took the "theoretically possible maximum" size as the desired size, even though I didn't have the memory to run that.
Fixing Open WebUI Timeouts with LiteLLM
The next problem I had was with Open WebUI hanging on the login screen when the Windows desktop was shutdown and there was no Ollama connection. I didn't want to mess with the AIOHTTP_CLIENT_TIMEOUT environment variable, because that would affect all the other endpoints.
Instead, I installed LiteLLM. This turned out to have several benefits over setting up Open WebUI connections directly.
First, it fixes the timeouts. I can now shut down the desktop machine and Open WebUI is fine.
Second, it gives me far more control. I have one connection that I need to manage in Open WebUI. I don't need the Anthropic Pipe installed any more. I no longer have 80 models floating around being set or unset, and I can change what Open WebUI sees by changing a config file under source control.
Third, I have much better observability. LiteLLM has integrated tracing and logging, and can even render logs in JSON format. This just relieves a lot of stress for me.
Important to note that this is not a general solution. Letta has to do some interesting mapping to manage state on top of stateless providers, so I can't just point Letta at LiteLLM and expect it to work. But it does take a lot of the pain out of managing Open WebUI.
Here's the gist of the ansible playbook I used for setting up LiteLLM.
Experimenting with Local LLMs
Once I had Letta working with Ollama again, I tried out a bunch of different models. The following is a partial list, and I'm still experimenting.
- thewindmom/hermes-3-llama-3.1-8b:latest - This is my go-to. It calls tools and answers questions with Letta, and it generally works. The problem is that it's trained on mermaid diagrams that use
A[text]instead ofA["text"]and so any diagrams with parens will fail, and my instructions to not do that aren't enough for it. - minchyeom/Letta-o1-Q8_0-GGUF - a model pretrained on Letta. This also worked, but it likewise couldn't handle mermaid diagrams.
- gemma2:9b-instruct-q6_K - This ate all of my GPU memory.
- Flow-Judge-v0.1-GGUF - Very clearly a small model for function calling, did not get cooking very well.
What it comes down to is that while Hermes 3 is very good at calling tools and answering general questions, it does not have the flair or the ability to follow instructions and address the user's needs in the way that Claude Sonnet does. Maybe I've been spoiled by relying on Claude, but I found going back to be a frustrating experience.
Leveraging External Models
While Claude Sonnet is great, I am still getting the feeling that it is too much gun. If I'm paying to run an external model I'd like to be able to pick the smallest possible model that gets the job done.
Some poking on the web showed that Lambda Labs has a serverless inference model that can give me a Hermes-3-Llama-3.1-70B model at $0.20 per 1M tokens of input or output. Comparatively, Claude Sonnet pricing is $3 per 1M tokens of input, and $15 per 1M tokens of output.
There's even cheaper options. As previously mentioned, Mistral is basically free if you're fine with the contract, and there's a variety of free options. Google AI studio is free, with 50 requests a day for the better experimental models. For Gemini Flash 2.0, you get 1500 responses. Groq has free and developer tiers, and OpenRouter has options for various free models.
Now that I have LiteLLM, I'm going to try them all out and see which one is the best for my needs.
Due Timers
And finally, there were times through cooking where Letta would tell me that something would be ready in five minutes, but it could not set a timer. I use Due, a timer app, but there is no direct integration between Letta and Due.
Due has a nice feature that uses hyperlinks to create timers. I set up a prompt to generate Due links.
Now I can say "Create a timer to check the broccoli in five minutes." and the system will respond:
Certainly! Here's a timer to check the broccoli in five minutes:
This timer will remind you to check the broccoli in 5 minutes from now. Simply click on the link to add it to your Due app.
And then I can click on the link and it will open Due and set the timer.
Once I had it working, I turned it into a custom tool that Letta can call when needed, and that cuts down on the overhead on the LLM.