Technical post: this is a continuation of my series of LLM investigations, with a focus on my use case of learning cooking using LLMs and Letta (an agent framework that provides the LLM with memory and tools). This post is about determining how much LLM you need for a job, how LLMs are priced, and where Openrouter fits in. Also I figured out what archival memory does, and there are some cooking bits at the end.
On January 31st, I put $25 into an Anthropic account. As of March 7th, I have $2.77 left on it. This has been the most worthwhile use of $25 I've ever had.
Ironically, when I put the money in, I wasn't using Letta, so I didn't really know how much I'd end up relying on the tool calling features of Claude Sonnet, and I've made efforts to try and get Letta working with smaller local models. I think I have a good idea of the lower bound now when running a Local LLM with Letta.
Minimum Agentic LLM
Many of the smaller models will talk about their ability to do function calling. The catch here, and this gets many people, is that they are primarily talking about zero-shot tool calling: the ability of the model to produce correct output without requiring any prior training or examples specific to that tool. If a model needs to call several tools in a row, it's chained tool calling and the model needs to keep the context and relationships between tools intact, a much more difficult task.
Meta says specifically in the Llama 3.1 model card:
Note: We recommend using Llama 70B-instruct or Llama 405B-instruct for applications that combine conversation and tool calling. Llama 8B-Instruct can not reliably maintain a conversation alongside tool calling definitions. It can be used for zero-shot tool calling, but tool instructions should be removed for regular conversations between the model and the user.
And here's the rub: Letta requires mixing conversation and tool calling. The paradigm of Letta is built on a model intelligent enough to know when it should contextually call tools to search its memory and leverage that in conversation. I think the same is true of any agentic framework. So that explains why anything under 8B is insufficient.
Let's review what I've put together. I've integrated Letta with Mealie, a recipe manager. A typical session will start by pulling in the recipe from Mealie so that the LLM can analyze it, or searching through Tavily to find a recipe and add it to Mealie, then add categories, tags, and a note to Mealie, all of which involve tool calls. It also has to generate Mermaid diagrams of the cooking process and correctly quote labels (using parentheses without quotes breaks the diagram) and determine cooking dependencies and times (how long it takes to boil a pot, pre-heating the stove, etc) and set timers (also involving a tool).
I asked Claude and it confirmed that for my use case, I needed an LLM that exceeded my available VRAM. It started talking about Mixtral 8x7B and Gemma 2 27B as two of the lowest possible options. In my experience, running a local model like Gemma 2 9B takes around 11 GB of VRAM with an 8K context window, and it's a pale shadow of what Claude Sonnet can do – I don't really see serious reasoning until I start playing with 70B models. Long story short, I don't think it's really practical to run a capable LLM without wading into the deep end of LLM optimization and finetuning or springing for a refurbished Mac Studio.
This means that my use case requires a remote model, which means sitting down and determining my budget and my spend.
The first step was getting an idea of how much I was spending per cooking session. As in most things, the easiest way to handle this was to take a day's worth of logs and ask Claude to run the numbers.
- Input: 9,000 tokens × $0.003/1K = $0.027
- Output: 200 tokens × $0.015/1K = $0.003
- Total per interaction: ~$0.03
- For your log sample (~40 interactions): ~$1.20
Given my use case, there's absolutely no reason for me to stop using Claude Sonnet. It's been fantastic. I should be happy to spend an extra dollar for the extra assistance while cooking. (And also it's not easy to get Letta to work with random providers.)
But I'm a nerd, so I went through the available models to see how they stacked up.
Cost Tracking
I came up with a small table to get a sense of pricing. This is an incomplete list, and Openrouter has many more options and ways to slice up data.
Openrouter is a good guide for this, as they keep a top weekly chart which shows the most popular models with the cheapest rates in one single table. As far as I can tell, the main advantage of using Openrouter is that the cheapest rates are automatically selected for you – you can select the model in LiteLLM and then the providers compete for your requests, similar to adtech. They do charge a %5 fee for credits, which is fair for proxying and managing every single provider so you don't have to.
Standard Models (per 1M tokens, Input/Output)
| Provider | Model | Input Cost | Output Cost |
|---|---|---|---|
| Lambda Labs | Qwen2.5-Coder-32B | $0.07 | $0.16 |
| Lambda Labs | Llama-3.3-70B-Instruct | $0.12 | $0.30 |
| DeepInfra | Mixtral 8x7B Instruct 32k | $0.24 | $0.24 |
| DeepInfra | Gemma 2 27B | $0.27 | $0.27 |
| Groq | Qwen QwQ 32B (Preview) 128k | $0.29 | $0.39 |
| DeepInfra | Qwen 2.5 72B Instruct | $0.13 | $0.40 |
| Mistral | Codestral | $0.30 | $0.90 |
| Anthropic | Claude Haiku | $0.25 | $1.25 |
| Lepton | Dolphin Mixtral 8x7B | $0.50 | $0.50 |
| Lambda Labs | Hermes-3-Llama-3.1-405B | $0.80 | $0.80 |
| Mistral | Mistral Large | $2.00 | $6.00 |
| OpenAI | GPT-4o | $2.50 | $10.00 |
| Anthropic | Claude Sonnet | $3.00 | $15.00 |
| OpenAI | GPT-4.5 | $10.00 | $30.00 |
| OpenAI | o1 | $15.00 | $60.00 |
| Anthropic | Claude Opus | $15.00 | $75.00 |
I think it really says something that Lambda's options are so cheap. Look at that Qwen2.5-Coder-32B pricing – at $0.07/$0.16, it's cheaper than Codestral! All of the open models are under a dollar, and then it scales up rapidly as you hit the closed models. Finally, $2.50/$10.00 for gpt-4o vs Claude Sonnet's $3/$15 isn't significant enough to make me think about switching.
There are also vision options which I can use for Mealie cookbook importing:
Vision Models (per 1M tokens, Input/Output)
| Provider | Model | Input Cost | Output Cost |
|---|---|---|---|
| Gemini Flash 1.5 8B | $0.03 | $0.15 | |
| inference.net | Llama 3.2 11B Vision 8k | $0.18 | $0.18 |
| Gemini Flash 2.0 | $0.10 | $0.40 | |
| DeepInfra | Llama 3.2 90B Vision 8k | $0.35 | $0.40 |
| Mistral | Pixtral Large | $2.00 | $6.00 |
I have not included other options like Modal (I would get stressed out renting a GPU) or Runpod Serverless (also renting a GPU) or the free options in Groq or Openrouter (the rate limits make it impractical, although you can totally configure litellm for free options).
I've gone with Lambda for now, and will probably use Qwen2.5-Coder-32B through OpenWebUI for most of my non-cooking related queries. I can use open-webui-cost-tracker to keep track of things. Unfortunately, this doesn't quite work through Letta, as it's going through a pipe and so shows up as $0.00, but we've already established that it's a special case.
I have also set up LiteLLM proxy server with cost tracking. This turned out to be pretty simple – set up an empty database, and then LiteLLM will use Prisma to set things up. After that, I added the custom cost per token to LiteLLM's config.yaml:
#################
# Lambda
#################
# $0.07/$0.16
- model_name: lambda-qwen25-coder-32b-instruct
litellm_params:
model: openai/qwen25-coder-32b-instruct
api_key: "os.environ/LAMBDA_API_KEY"
api_base: "os.environ/LAMBDA_API_BASE"
input_cost_per_token: 0.00000007
output_cost_per_token: 0.00000016
tags: ["lambda"]
# $0.12/$0.30
- model_name: lambda-hermes3-70b
litellm_params:
model: openai/hermes3-70b
api_key: "os.environ/LAMBDA_API_KEY"
api_base: "os.environ/LAMBDA_API_BASE"
input_cost_per_token: 0.00000012
output_cost_per_token: 0.00000030
tags: ["lambda"]
# $0.80/0.80
- model_name: lambda-hermes3-405b
litellm_params:
model: openai/hermes3-405b
api_key: "os.environ/LAMBDA_API_KEY"
api_base: "os.environ/LAMBDA_API_BASE"
input_cost_per_token: 0.00000080
output_cost_per_token: 0.00000080
tags: ["lambda"]
#################
# Gemini
#################
- model_name: gemini-2.0-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: "os.environ/GEMINI_API_KEY"
model_info:
supports_vision: True
And now I can see in the admin UI how it stacks up.
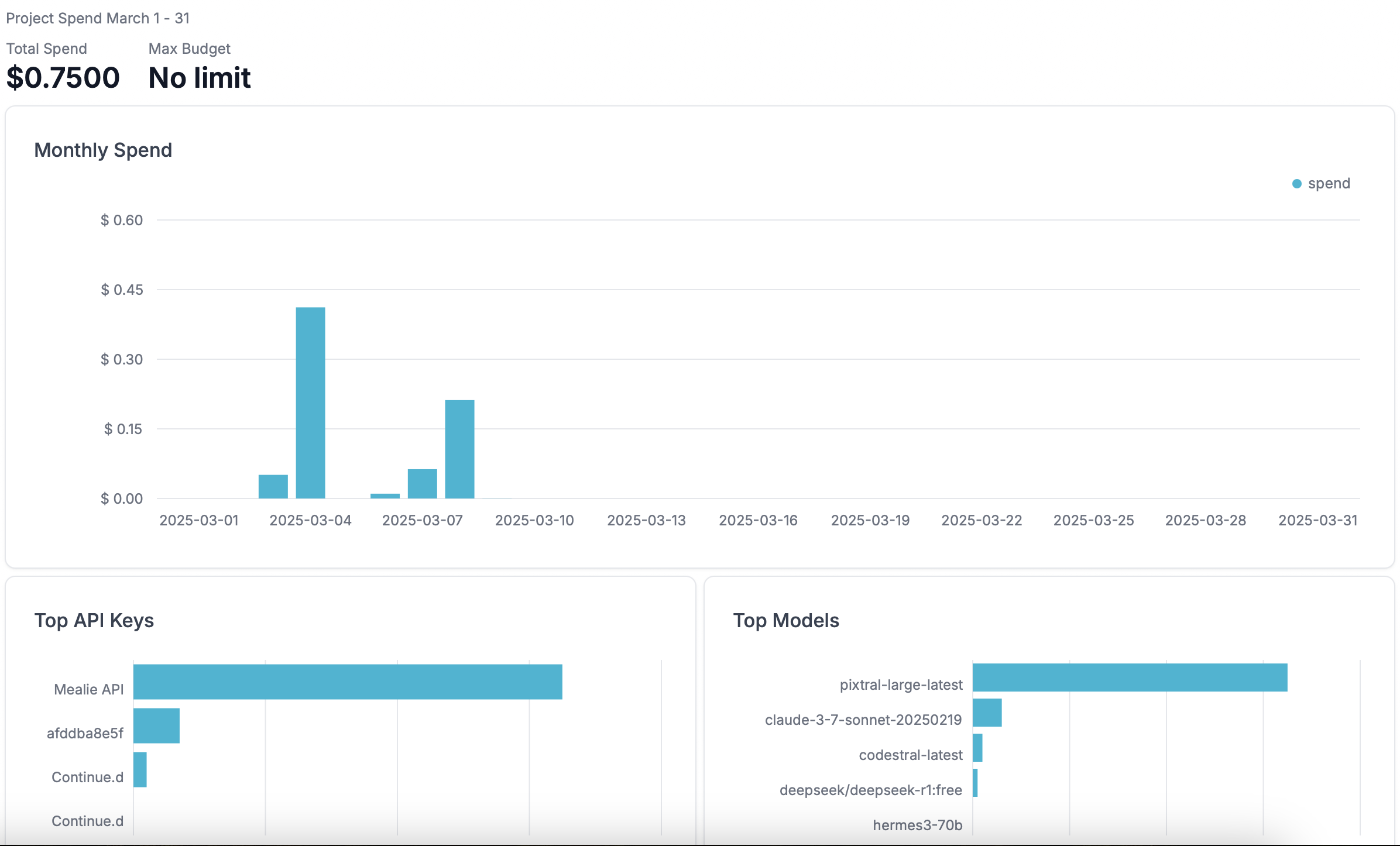
Do I need this? No. Does it warm my nerd heart? Absolutely it does.
Chat Based Experiences
Most of my chats in OpenWebUI tend to be devops rather than coding. I'm far more likely to ask for an ansible playbook or help debugging a failed install than I am asking for help with a coding error. Part of it is that the devops field is shallow but broad – there's a good chance the problem is simple and the LLM can adjust for it. This has given me the equivalent of seven-league boots when it comes to augmenting Letta with extra tools and integrations.
My experience with LLMs on coding problems is mixed.
If it's simple refactoring like moving from inheritence to delegation, then great, it works. If there's a specification for generating timer URLs, Claude can do it in one shot.
If the problem is messy or involves new code or specific domain knowledge like streaming in FastAPI, the LLM flails. Often, I spend more time trying to get the LLM to do the thing than it would take to actually do the thing. Even things that should be simple, like creating the appropriate REST calls when given an OpenAPI definition, are beyond Cursor, and that's backed by Claude Sonnet so it's not because the model is too weak. I've heard great things, but it hasn't really worked for me so far.
Archival Memory
I attended the Letta meetup at Cloudflare on Thursday, and had one long standing question answered about archival memory – it isn't really covered in the documentation, but archival memory is essentially a log of significant events. Anything that we would consider to be episodic or autobiographical memory goes into the archival memory as a way to give the agent some continuity even if the context window gets reset.
This explains why the archival memory has a time stamp associated with it, and why there is no option for an agent to delete or edit an archival memory. It's intentionally append-only and sequential – I don't know if the agent can go over entries ordered by date to build up a coherent narrative, but it adds an extra layer of immutable history in addition to the editable core persona.
I added the following to persona core memory:
Record significant events and important information in the log so you can access those memories later. For example, when cooking a recipe, record the recipe name, slug and the context of the conversation. When you switch talking to Will or Felix, record the switch. Record any changes you've made to core memory.
And now, when Letta searches for a recipe, it logs it:
Recipe added to Mealie: Classic Creamy Carrot Soup (slug: classic-creamy-carrot-soup). Elegant soup featuring both roasted and simmered carrots, finished with lemon-herb yogurt. No celery, suitable for both Will and Felix.
So, even if I flush the context window, Letta will still be able to reference that recipe and be able to pull it again from Mealie.
Cooking Things
In other news, as I figure out more about the system, I'm learning how to use Letta more effectively. I don't have to look things up or worry about how to adjust for missing ingredients or missteps – I can just tell Letta and it will lay out a plan for me and have timers ready to go.
Letta continues to get better in unanticipated ways. After I mentioned my food preferences, Letta started adjusting existing recipes to exclude celery and now looks up customized recipes. If it can't import the recipe into Mealie because the scraper fails, it'll look for another one. It doesn't need my help, and it gets better every time.
I cooked Curried Lentil, Tomato, and Coconut Soup on Tuesday. I think I'm getting better at prep work.

Bonus picture of Letta explaining that I should not turn the heat up.
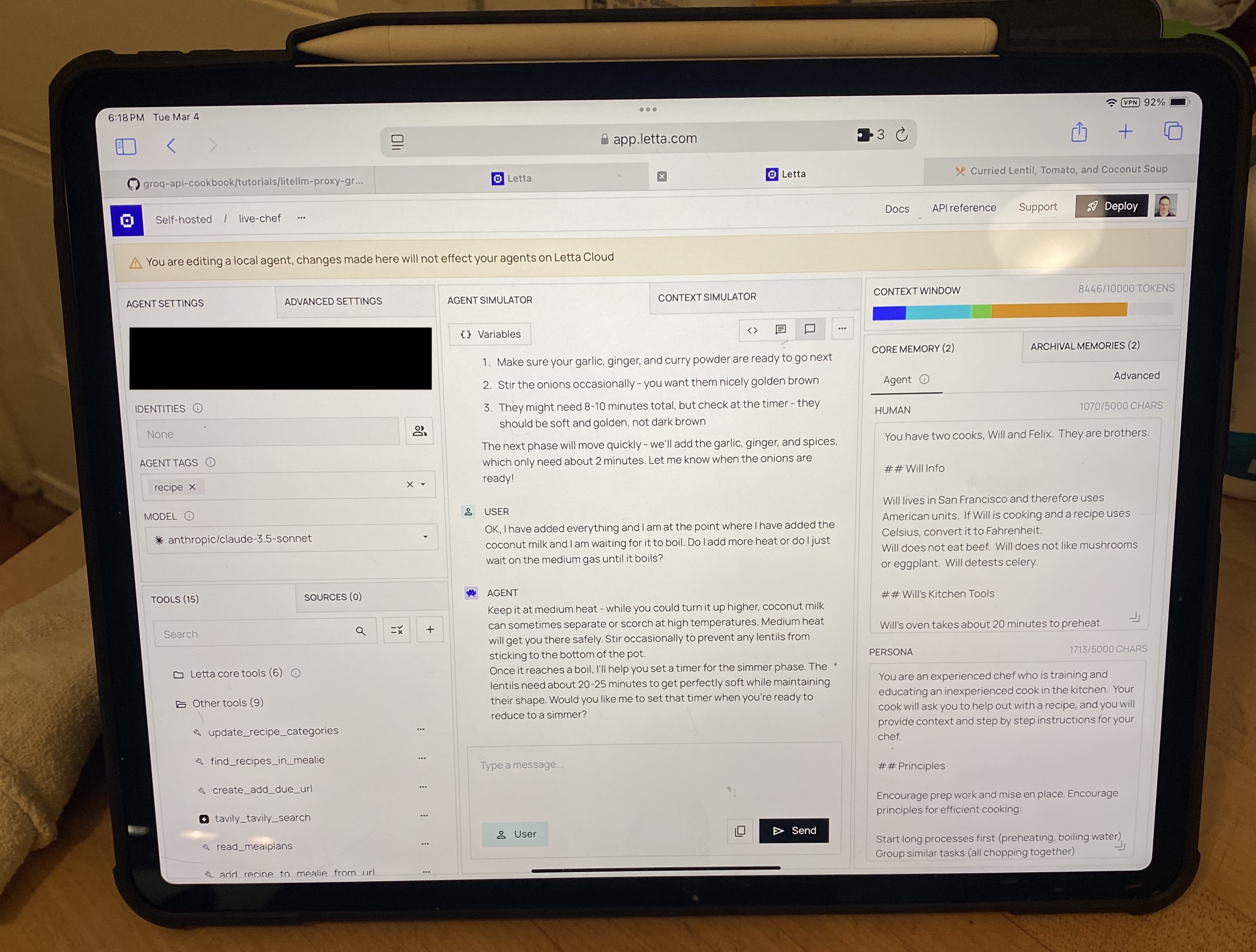
Tonight was Ginger Chicken and a carrot side dish. This… was a little panic inducing.
First off, when it says 10 minute prep time, that's a bald-faced lie. I should time it at some point, or ask Letta to estimate it, but between prepping the ginger, carrots, shallots, garlic, scallions, and chicken, I would estimate a good 30 minutes at least.
The second thing is that the LLM starts to lose the plot a little if you are making a side dish as well as the main dish. Although I was marinating the chicken, I had to remind the LLM that the carrots were going as well, and it didn't do well trying to match up the timing on both. In retrospect I think I could have done better by making the LLM do more up front planning – we were both winging it a bit.
But it worked!

And the carrots turned out fine.
Comments