This is going to be a more technical blog post: I'm documenting the work of putting together a locally based large language model (LLM) to help me with recipes and cooking. You can read my last post for details.
Using Open WebUI has been a good choice, but there are some glaring limitations in using LLMs once you start using them in earnest. The biggest one is that LLMs have no memory. This is a problem for me, because I want my LLM to be able to understand my context: I have a rice cooker, I prefer steaming things in the microwave to boiling or blanching, I have this food in the fridge. I don't want to have to keep telling it this.
This is a good place to start talking about how LLMs work and give a brief rundown of the internals. The underlying architecture of LLMs and generative AI is really interesting once you get into it, and it should explain why I'm doing it this way.
How LLMs Work
A large language model is basically a stateless function that consumes text as an input and produces text as an output. It does this by converting words and symbols into tokens, each token represented by a multi-dimensional set of numbers. An LLM consumes text by placing it into the context window, but that is limited to a set number of tokens, and larger context windows take far more time and processing power to execute.
When you hold a conversation with an LLM, every single message in the chat is sent to the context window of the LLM for processing. It does not hold the previous messages in memory – it must read through the entire thing over again, every time. This has consequences: there's an upper limit to how long your conversations can be, and the more you talk, the more text there is for the LLM to process and the slower it gets.
graph TD
A[New Input] --> B
B --> C{LLM Processing}
subgraph Context Window
B[New Input Message]
D[System Message<br>'You are a helpful assistant...']
E[Previous User Message 1]
F[Previous LLM Response 1]
G[Current User Message]
end
D --> C
E --> C
F --> C
G --> C
C --> H[Token Generation]
H --> I[LLM Response Output]
style B fill:#f0f0f0,stroke:#333
style C fill:#e1f5fe,stroke:#0288d1
style D fill:#e8f5e9,stroke:#4caf50
style H fill:#fff3e0,stroke:#ff9800
There is no memory outside of this. If it's not in the context window, it doesn't exist.
So, how do LLMs do things on their own if they can only produce text? As far as I know (and I am still learning this), there are two strategies: they can talk to the program running the LLMs, and they can talk to themselves. Between these two options, LLMs can essentially fake memory.
Function Calling
When the LLM produces a message intended for to be processed by the program, that is called a tool message. Usually the tool message is set up in the form of structured output like JSON, and contains the method and arguments that the LLM would like the program to execute on its behalf. Once the tool is executed, the result is passed back to the LLM (again, in structured text output), and the LLM then produces a response back to the user, or makes other tool calls as appropriate.
sequenceDiagram
participant User
participant LLM
participant Environment
User->>LLM: Task Input
Note over LLM: Analyze task and<br/>determine tool needed
LLM->>Environment: Tool Call {function, args}
Note over Environment: Execute function<br/>with arguments
Environment->>LLM: Tool Result
Note over LLM: Process result and<br/>formulate response
LLM->>User: Final Response
This approach is called function calling and usually requires the LLM to be sufficiently advanced (at least 3 billion parameters) enough to understand what tools it has, and how and when to call them appropriately. There are some LLMs, such as Hermes 3, that explicitly tout their ability to do function calling reliably, and there is even a function calling leaderboard.
The question of how the LLM knows that it has tools available is that it is told explicitly, in English, what the tool is and how it works.
Here's a example of function calling to ask what's in the kitchen:
You are a function calling AI model. You are provided with function signatures within
XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools:
<tools>
{"type": "function", "function":
"name": "get_kitchen_inventory"
"description":"get_kitchen_inventory(category: str) -> dict
- Get current inventory data for kitchen items by category using local database.
Args:
category (str): The category to query ('ingredients', 'appliances', or 'all').
Returns:
dict: A dictionary containing inventory data.
Keys:
- 'ingredients': List of available ingredients with:
- 'name': Name of ingredient
- 'amount': Quantity available
- 'unit': Unit of measurement
- 'expiry_date': Expiration date if applicable
- 'appliances': List of available cooking equipment with:
- 'name': Name of appliance
- 'type': Type of appliance (e.g., 'cooker', 'processor')
- 'max_capacity': Maximum capacity if applicable
- 'features': List of special features
- 'last_updated': Timestamp of last inventory update",
"parameters": {"type": "object", "properties": {"category": {"type": "string", "enum": ["ingredients", "appliances", "all"]}}, "required": ["category"]}}
</tools>
Use the following pydantic model json schema for each tool call you will make:
{"properties": {"arguments": {"title": "Arguments", "type": "object"}, "name": {"title": "Name", "type": "string"}}, "required": ["arguments", "name"], "title": "FunctionCall", "type": "object"}
For each function call return a json object with function name and arguments within
XML tags as follows:
<tool_call>
{"arguments": {"category": "all"}, "name": "get_kitchen_inventory"}
</tool_call>
It is very strange that we are using English to tell a program how to talk to another program, but again, the LLM has no way to understand anything that isn't convertable into tokens. If you are relying on the LLM to make contextualy appropriate calls for you, this is basically it.
Function calls are not free. They add to the amount of work that the LLM has to do, and they set a floor on how simple and stupid the LLM can be. Function calls are important and necessary because they allow the LLM to manage its context window. By calling a function and adding the result to its context window, the LLM can know things that you haven't explicitly told it. This is key for retrieval augmented generation (RAG) which applies function calling to databases and search engines, typically using similarity searches based on embedding models and vector databases for leverage.
Self Calling
Because the LLM has the ability to call tools, we can create tools which enable the LLM to talk to themselves and leave notes.
For example, we can create a tool that says "store some relevant information about this chat" and when its called, the program puts it in a datastore (database or memory) and returns success. Later, the LLM can query for that information in another chat and recall it.
This is basically the Memento strategy applied to LLMs: you wake up every day as an amnesiac, and you work out who you are and what you're supposed to do from the notes to yourself.
Now that we have function calling and self messaging, we essentially have a basic form of memory.
sequenceDiagram
participant User
participant LLM
participant Memory
Note over Memory: Stores previous<br/>interactions
User->>LLM: Input Message
LLM->>Memory: Retrieve relevant context
Memory->>LLM: Return context
Note over LLM: Process input with<br/>retrieved context
LLM->>User: Response
LLM->>Memory: Store interaction
However, memory is more complex than that, and there's different forms of memory that are needed to be effective.
MemGPT
The full suite of memory is detailed in the MemGPT paper that describes four different kinds of memory: core, message, archival, and recall, at different levels of priority.
sequenceDiagram
participant User
participant MemGPT
participant Core Memory
participant Message Memory
participant Archival Memory
participant Recall Memory
Note over Core Memory: System Prompt<br/>Persona<br/>Core Context
Note over Message Memory: Recent Messages<br/>(Fixed Size Buffer)
Note over Archival Memory: Long-term Storage<br/>(Vector Database)
Note over Recall Memory: Dynamic Memory<br/>(Search Results)
User->>MemGPT: Input Message
MemGPT->>Message Memory: Check context window space
alt Context window full
MemGPT->>Archival Memory: Store oldest messages
Message Memory->>Message Memory: Free up space
end
MemGPT->>Core Memory: Load core context
MemGPT->>Message Memory: Load recent messages
MemGPT->>Archival Memory: Search relevant memories
Archival Memory->>Recall Memory: Load relevant memories
Note over MemGPT: Process all memory<br/>streams together
MemGPT->>User: Generate Response
MemGPT->>Message Memory: Store interaction
alt Memory management needed
MemGPT->>Archival Memory: Archive important information
MemGPT->>Message Memory: Clean up old messages
end
Although there's a lot here, there are some interesting features in MemGPT in how long term memories are consolidated. Although archival memory is unbounded, an LLM can only fit so much in its context window and needs to consolidate relevant information, so at periodic intervals it will summarize and prioritize information as relevant. One nice detail is that because everything is text, you don't have to guess what MemGPT remembers – you can just go read old memories in the database, and it will have the general structure without the details.
Adding Memory
The implementation of MemGPT is called Letta. It's open source and can run locally. It's easy enough to install using the Docker quickstart, but I didn't want to have the PostgresSQL database inside the same VM as Letta because I have a tendency to type vagrant destroy when upgrading and futzing with things.
Here's the Letta playbook and the pgvector playbook. Note that in order to use their Cloud API Development platform, you must expose your Letta endpoint for public access, so you must use the SECURE flag.
Once i had Letta installed, I installed the Letta pipe and created an agent – and I had an LLM with memory!
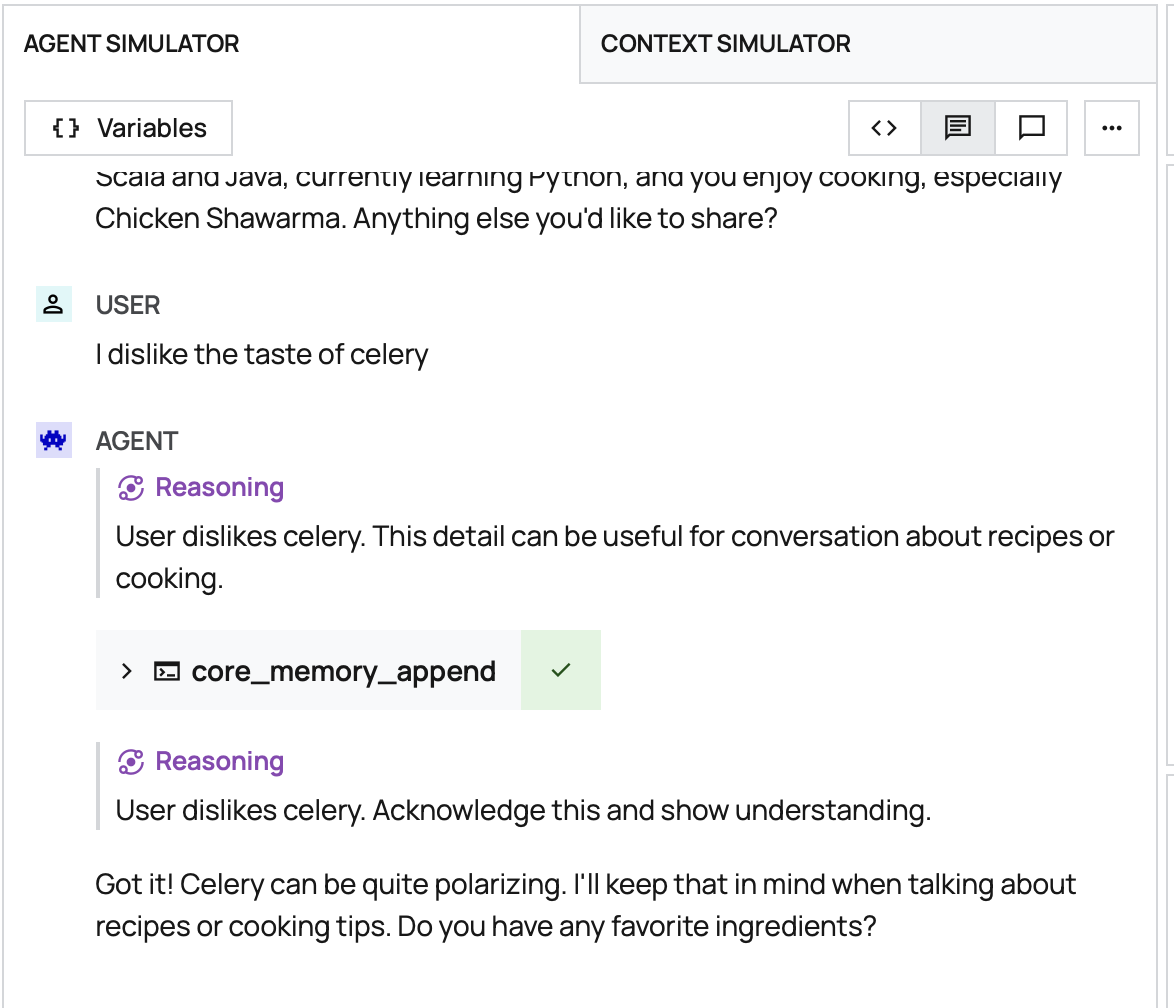
There's very little I can do with this agent right now, but the next step is to give it recipe information and have it work through cooking with me step by step.
Comments