There's a lot of confusion around execution contexts and how they work in Scala. The description in Futures and Promises does a good job of explaining the concept of how Futures work, but does not explain what the difference is between ExecutionContext.global, ExecutionContext.parasitic, and ExecutionContext.opportunistic, and where and when you would want to use these.
ExecutionContext.global
Let's start off by explaining what execution contexts and executors actually do, starting with the global execution context. Here's the simplest possible program:
package example
import scala.concurrent.duration.Duration
import scala.concurrent.{Await, ExecutionContext, Future}
object Exercise1 {
private val logger = org.slf4j.LoggerFactory.getLogger(getClass)
def main(args: Array[String]): Unit = {
val f = Future {
Thread.sleep(1000) // simulate a blocking operation.
logger.info("Executed future!")
}(ExecutionContext.global)
// block until the future completes
Await.ready(f, Duration.Inf)
}
}
The relevant bit is the Future(...)(ExecutionContext.global). This says to use the global execution context for the block in the Future. Under the hood, the execution context turns the block into a Runnable and calls executor.submit on it.
If you wanted to do it in a Java style, Future would look roughly like this:
val runnable = new Runnable() {
override def run = {
Thread.sleep(1000)
logger.info("Executed future!")
}
}
globalExecutor.execute(runnable)
When you run this program, you'll get a log statement like:
13:27:48.832 example.Exercise1$ INFO [scala-execution-context-global-21]: Executed future!
Note that scala-execution-context-global-21 thread name – the global execution context has its own internal executor, which manages its own threads. The executor can technically do anything it wants to execute the runnable in any order, using any thread pool. Most executors will put the runnable on a task queue, which can either be bounded – they have a maximum size and will reject tasks if the queue is full – or unbounded – you can keep adding tasks until the JVM runs out of memory.
The goal of concurrency is to use as few resources as you can get away with, including threads. Creating threads and context switching between threads is expensive, and so for fork/join pools you want only as many threads as you have CPU cores. In addition, the more executor services you're using, the more work the system has to do to manage.
Using a Future.apply here is technically an anti-pattern. In production code, kicking off a Future is almost always done by an external service – either you're calling a database and waiting for a result, or you're accumulating a stream of bytes that will eventually turn into a parsable format, or you're using a callback service like GRPC and writing to a Promise. These external services will typically manage their own thread pools. In the majority of cases, you'll be dealing with the transformation of an existing Future, rather than creating your own.
Let's look at two futures:
object Exercise2 {
private val logger = org.slf4j.LoggerFactory.getLogger(getClass)
def main(args: Array[String]): Unit = {
import ExecutionContext.Implicits.global
val f1 = Future {
logger.info("Executed future1!")
}
val f2 = Future {
logger.info("Executed future2!")
}
val f1andf2 = f1.zip(f2)
Await.ready(f1andf2, Duration.Inf)
}
}
The two futures are created and placed into the task queue, and the global execution context attempts to run them at the same time:
13:35:00.235 example.Exercise2$ INFO [scala-execution-context-global-21]: Executed future1!
13:35:00.235 example.Exercise2$ INFO [scala-execution-context-global-22]: Executed future2!
Note that there's no requirement that f1 and f2 execute in order: concurrency means they can happen in any order, and parallelism means that they can both execute at once. Here, the futures executed in parallel, each using a different thread on a different CPU core.
Because Scala considers Future[_] to produce a value at some point in the future, all computations have to be through operators that compose Future[_], notably flatMap and map. Each of these also takes an implicit execution context, and is turned into a Runnable under the hood.
import ExecutionContext.Implicits.global
val f = Future {
val s = "f1"
logger.info(s)
s
}.map { s =>
val s2 = s + " f2"
logger.info(s2)
s2
}.map { s2 =>
val s3 = s2 + " f3"
logger.info(s3)
}
When we run this, all the map statements take the global execution context, and are executed sequentially because they depend on output.
14:12:14.406 example.Exercise3$ INFO [scala-execution-context-global-21]: f1
14:12:14.408 example.Exercise3$ INFO [scala-execution-context-global-21]: f1 f2
14:12:14.408 example.Exercise3$ INFO [scala-execution-context-global-21]: f1 f2 f3
Whenever you have a Future block, you're using a Runnable. Whenever you're using map, flatMap, and so on, that's essentially jamming a bunch of Runnable together.
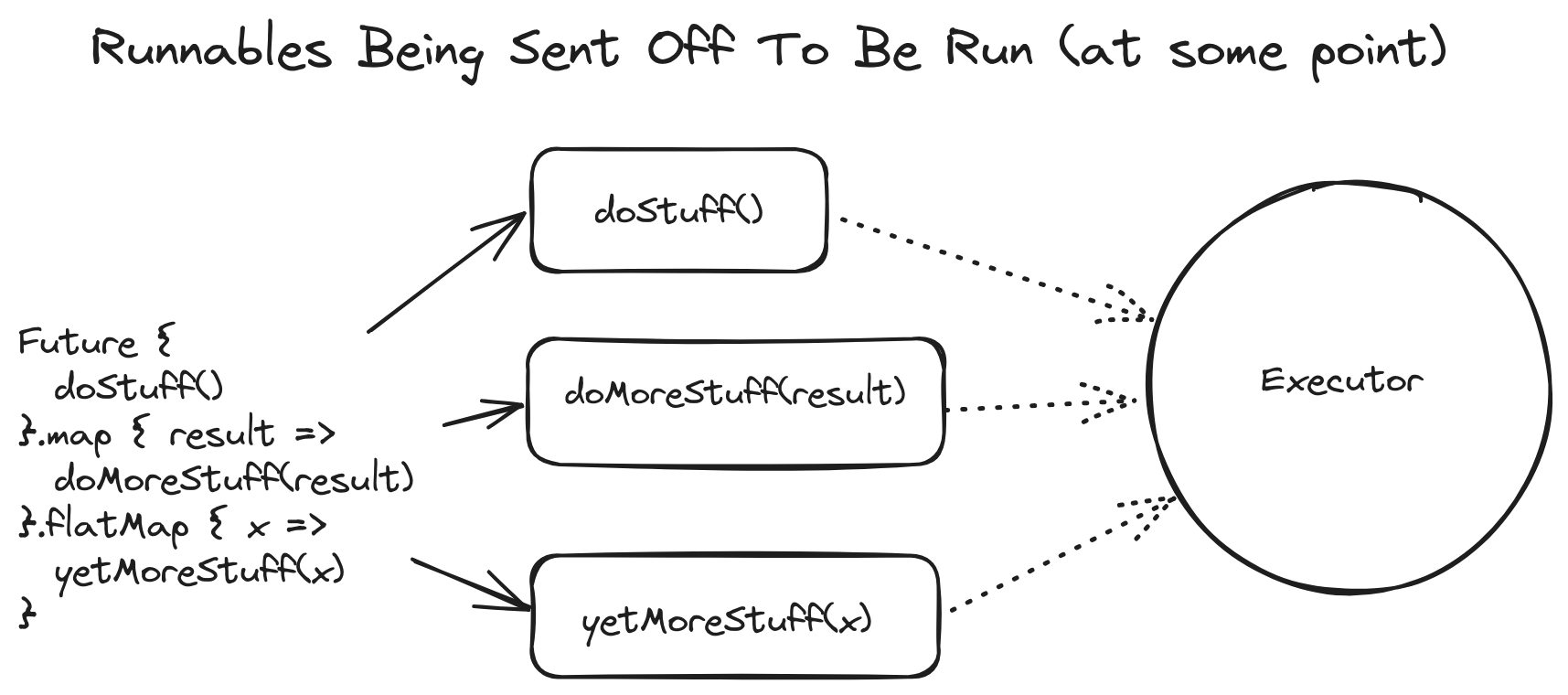
Note that these can run on the same thread, but it's entirely possible that each of these tasks run in a different thread. This can be needlessly expensive, as a context switch between threads incurs an overhead for what should be a straightforward operation.
Finally, ExecutionContext.global creates a ForkJoinPool for its executor, with some tweaks to size it for the CPU cores. A more detailed breakdown of the internals can be found here, but that's basically it.
There is a blocking construct that can improve parallelism, but I have never seen this used in production code – it's more maintainable to just use a dedicated custom execution context that's tuned for IO.
ExecutionContext.parasitic
The problems with Future underperforming in some scenarios were well known, and in 2.13 there were a bunch of changes to streamline and optimize performance.
One solution to this is to use a "synchronous" execution context, also known as a trampoline execution context. In 2.13, this is ExecutionContext.parasitic.
The pull request for ExecutionContext.parasitic explains the underlying mechanism: if the future is completed, it will run on the registering thread, and if the future is not yet completed, it will run on the completing thread.
This means that parasitic – despite being "synchronous" – is still not a solution to using execution contexts in conjunction with thread local storage. You will run into problems if you use an unmanaged parasitic with a system that relies on thread local storage, such as MDC or Opentelemetry.
For example, if we use parasitic here:
object Exercise4 {
private val logger = org.slf4j.LoggerFactory.getLogger(getClass)
def toIntFuture(f: Future[String]): Future[Int] = {
Thread.sleep(1000)
f.map { s =>
logger.info(s"toIntFuture: converting $s")
s.toInt
}(ExecutionContext.parasitic)
}
def main(args: Array[String]): Unit = {
val stringFuture = Future {
logger.info("starting!")
"42"
}(ExecutionContext.global)
val f = toIntFuture(stringFuture)
val result = Await.result(f, Duration.Inf)
logger.info(s"result = $result")
}
}
Then the map runs on the main thread.
19:28:39.413 example.Exercise4$ INFO [scala-execution-context-global-21]: starting!
19:28:40.414 example.Exercise4$ INFO [main]: toIntFuture: converting 42
19:28:40.467 example.Exercise4$ INFO [main]: result = 42
But move the Thread.sleep:
object Exercise4 {
private val logger = org.slf4j.LoggerFactory.getLogger(getClass)
def toIntFuture(f: Future[String]): Future[Int] = {
f.map { s =>
logger.info(s"toIntFuture: converting $s")
s.toInt
}(ExecutionContext.parasitic)
}
def main(args: Array[String]): Unit = {
val stringFuture = Future {
logger.info("starting!")
Thread.sleep(1000)
"42"
}(ExecutionContext.global)
val f = toIntFuture(stringFuture)
val result = Await.result(f, Duration.Inf)
logger.info(s"result = $result")
}
}
And you'll see parasitic run on the global execution context.
15:05:56.776 example.Exercise4$ INFO [scala-execution-context-global-21]: starting!
15:05:57.779 example.Exercise4$ INFO [scala-execution-context-global-21]: toIntFuture: converting 42
15:05:57.789 example.Exercise4$ INFO [main]: result = 42
The parasitic execution context is both useful and dangerous. Not only does it reduce the chance of a context switch, but it can also simplify code. For example, it's common for methods to look like this:
class FooService @Inject()(fooDAO: FooDAO)(implicit ec: ExecutionContext) {
def getAge(id: ID): Future[Int] = {
fooDAO.get(id).flatMap { foo =>
foo.age
}
}
}
In this situation, the long-running operation to get a Foo shouldn't need an execution context just to map from foo to foo.age. Using parasitic for trivial maps like these and removing the class scoped implicit encourages each method to think about how to handle calls.
class FooService @Inject()(fooDAO: FooDAO) {
def getAge(id: ID): Future[Int] = {
fooDAO.get(id).flatMap { foo =>
foo.age
}(ExecutionContext.parasitic)
}
}
However, you must be careful about how much work you're doing in the flatMap. The DAO will probably be using a ThreadPoolExecutor internally to manage queries to the database. If you use parasitic to piggyback a flatMap and are tying up the thread with complex logic, then you are taking resources away from the DAO's internal thread pool and also losing out on the work-stealing advantages you would gain by using a fork/join pool,
class FooService @Inject()(fooDAO: FooDAO) {
def unsafeMethod(id: ID): Future[Int] = {
fooDAO.get(id).flatMap { foo =>
complexAnalytics(foo) // potentially long-running CPU-bound work
}(ExecutionContext.parasitic) // unsafe to use parasitic here
}
}
Similarly, you should only use parasitic when you control the executing block's logic. You should not use parasitic where you have a function or call-by-name parameter, for example, as these could block.
def unsafe(f: String => Int): Future[Int] = {
// we don't control execution here, so technically f could block or be expensive.
internalFuture().flatMap(s => f(s))(ExecutionContext.parasitic)
}
In this situation, you should be passing in an execution context as an implicit, as only the caller will know what the function does.
Managing Executors
One problem with ExecutionContext is that it is a blank sheet of paper. There's nothing to indicate what executor is actually at work, or when it's time to switch to a different executor.
One useful technique in managing executors is to associate them with strongly typed execution contexts. For example, Play has a CustomExecutionContext that can be extended with your own custom types.
class DatabaseExecutionContext @Inject()(system: ActorSystem) extends CustomExecutionContext(system, "database-dispatcher")
abstract class CustomExecutionContext(system: ActorSystem, name: String) extends ExecutionContextExecutor {
private val dispatcher: MessageDispatcher = system.dispatchers.lookup(name)
override def execute(command: Runnable) = dispatcher.execute(command)
override def reportFailure(cause: Throwable) = dispatcher.reportFailure(cause)
}
class DatabaseService @Inject()(implicit executionContext: DatabaseExecutionContext) {
// ...
}
This is not only useful in making sure that you know what execution context you're looking at, but it also helps in the logs, because the thread name will show up as database-dispatcher-1.
Rather than using an implicit parameter, you can use singletons, and use ArchUnit to enforce your ExecutionContext style.
BatchingDispatcher and ExecutionContext.opportunistic
In addition to ExecutionContext.global and ExecutionContext.parasitic, there's also ExecutionContext.opportunistic, although you'll need to do some work to dig it out.
The official documentation for opportunistic is attached to the global scaladoc under the "Batching short-lived nested tasks" section. You can read the source code if it's easier.
The documentation primarily consists of the following:
ExecutionContext.opportunisticuses the same thread pool asExecutionContext.global. It attempts to batch nested task and execute them on the same thread as the enclosing task. This is ideally suited to execute short-lived tasks as it reduces the overhead of context switching.
There's a story attached to why opportunistic is not public.
The story begins with the pull request Make the global EC a BatchedExecutor (performance). This PR made the global execution context implement BatchingExecutor, which is what implements this batching behavior.
Then, it was discovered that Nested Future blocks do not run in parallel in Scala 2.13.x, and it was A Thing.
This was unpopular, and the behavior was reverted in Revert ExecutionContext.global to not be a BatchingExecutor. Then ExecutionContext.opportunistic was added as a fallback for the batching behavior, but kept as private[scala] so it wouldn't break binary compatibility. And it remains in that state to this day.
ExecutionContext.opportunistic represents a middle ground between global and parasitic where the execution will use a thread if it has to, but then try to keep everything on that thread. This is similar to the behavior you get if you use an Akka actor's context.dispatcher, although they are still distinct implementations.
object Exercise5 {
val opportunistic: scala.concurrent.ExecutionContext =
(scala.concurrent.ExecutionContext: {def opportunistic: scala.concurrent.ExecutionContextExecutor}
).opportunistic
private val logger = org.slf4j.LoggerFactory.getLogger(getClass)
def slow(key: String): Future[String] = Future {
logger.info(s"$key start")
Thread.sleep(1000)
logger.info(s"$key end")
key
}(opportunistic)
def runAsyncSerial(): Future[Seq[String]] = {
implicit val ec = opportunistic
slow("A").flatMap { a =>
Future.sequence(Seq(slow("B"), slow("C"), slow("D")))
}
}
def main(args: Array[String]): Unit = {
val f = runAsyncSerial()
val result = Await.result(f, Duration.Inf)
logger.info(s"result = $result")
}
}
This renders all the futures on a single thread.
17:52:10.651 example.Exercise5$ INFO [scala-execution-context-global-21]: A start
17:52:11.653 example.Exercise5$ INFO [scala-execution-context-global-21]: A end
17:52:11.667 example.Exercise5$ INFO [scala-execution-context-global-21]: D start
17:52:12.668 example.Exercise5$ INFO [scala-execution-context-global-21]: D end
17:52:12.669 example.Exercise5$ INFO [scala-execution-context-global-21]: C start
17:52:13.669 example.Exercise5$ INFO [scala-execution-context-global-21]: C end
17:52:13.670 example.Exercise5$ INFO [scala-execution-context-global-21]: B start
17:52:14.671 example.Exercise5$ INFO [scala-execution-context-global-21]: B end
17:52:14.677 example.Exercise5$ INFO [main]: result = List(B, C, D)
Would I recommend using ExecutionContext.opportunistic? Well, no.
Using ExecutionContext.opportunistic implies using ExecutionContext.global. It assumes that you do not have your own dispatchers lying around. It also relies heavily on the correct usage of the blocking construct on any long-running and/or blocking tasks.
- If you are using Akka/Pekko (or Play), you'll leverage the default dispatcher, which already implements
BatchingExecutor. - If you have defined your own execution contexts, you cannot apply
scala.concurrent.BatchingExecutortrait to it as it is private. You cannot make your own opportunistic executor. - If you know you have long running or blocking tasks, it's easier to use a dedicated
ThreadPoolExecutorover using theblockingconstruct – you can see the thread names and manage thread allocation. - If you have short-lived tasks, it's easier to use
ExecutionContext.parasitic.
Given all of that, the only appropriate place I can see ExecutionContext.opportunistic being used is in a situation where the application has enough concurrency going on that context switching is a problem, but also not enough design in managing concurrent tasks to define and isolate different execution contexts, while also appropriately wrapping long-running/blocking code in a blocking construct. While also not using Akka/Pekko, or using one of the other concurrency management libraries like Cats IO or Monix.
Comments