TL;DR
You can log JSON to PostgreSQL using the JSONB datatype. Appending structured data to a database has a number of advantages over logging to a flat file, such as viewing, searching, filtering, and sorting JSON becomes much easier in a database format.
In particular, you can start querying your logs in IntelliJ IDEA:
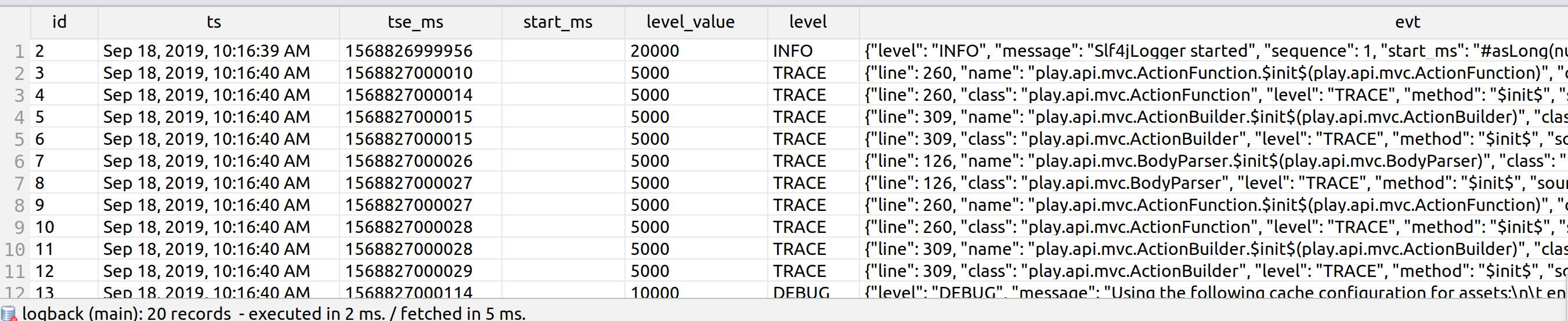
Overview
When you're a developer, you're typically logging to disk. If you're not logging to disk, you're typically working on an EC2 instance in the cloud and your logs are going to a central ELK stack. When you're working with JSON logs, especially when you have microservices that are all logging at once, this is no fun. You're grepping for text on the filesystem or working through HTML forms, using something that wasn't designed to work with you. If you're a developer, then you query, sort and correlate data all the time. Logs are like any other data – why can't you process it like any other data?
Databases are the OG data processing system. Logs, particularly semi-structured data like JSON are data. It's extremely simple to setup PostgreSQL, create a user and schema, and start logging. PostgresSQL has excellent support for JSON and there's a cheat sheet. And because logs are inherently time-series data, you can also use the timescaleDB postgresql extension as described in this blog post.
The reasons why people don't use databases are operational (database input can be a bottleneck) and contextual – you need structured data, and the operational ecosystem assumes ELK/Splunk as an endpoint. But databases just work, particularly in a developer or staging context where you are not as bound by operational constraints as you are in production.
Once you've got logging going to a database, you immediately have a number of tools available to you that weren't there before.
Viewing
First, you can view the data you want in the format you want. Viewing JSON data is fiddly enough that there are a number of NDJSON log viewers out there: but by and large, they are console based. There are also GUI log viewers, but they're typically line oriented, and don't have any facility to transform nested JSON for display purposes.
PostgreSQL JSON solves all of this in one stroke. With JSON selects, you can create multiple views that show exactly the data that you want in the format that you want it, and work with it through IntelliJ IDEA Database Navigator, or any number of database GUI clients.
Searching
Searching for a particular field in PostgreSQL is of course trivial. The fields are already indexed, so the overhead of grepping raw text is ameliorated, and for more complex queries you can do an EXPLAIN PLAN to show how PostgreSQL is running that query or use pg_stat. You can do fairly fancy things with JSON so it's just as useful as SQL, although the syntax is a bit strange (Postgres 11 will use jsonpath natively when it comes out).
In a microservices framework, you can write data into different tables, and then join on the correlation id to see the flow of a request instantly. You can track any id through every service, and expose JSON payloads as top level items. If you're willing to do some extra work, you can even include lookup tables so you can map those IDs to usernames and emails in the queries.
Aggregation
Because PostgreSQL is a real database, you can perform aggregate calculations to see how various requests break down. If you're using tracing, you might want to see the 10 slowest requests, for example, or see the average request duration grouped by browser. You can aggregate over arrays, and aggregate JSON object values.
Storage
One of the common complaints about files is that they can be large and unwieldy – even Visual Studio Code will complain about 1 GB JSON files. All of this goes away when you use a database. You can truncate everything past a deadline, or just delete everything except a couple of threads you care about. In PostgreSQL 10, you can even physically partition tables while maintaining the same logical view, which can be used to partition by date ranges.
Backfilling
One of the things that I've talked about is the concept of triggering diagnostic logging on exception, which sets up the logging system with a ringbuffer of diagnostic (DEBUG and TRACE) logging events in memory, but only serializes those events when an exception occurs.
Although this is a great idea in general, there's some awkwardness in how this is implemented in a flat file logging system. When the exception happens, the diagnostic events have already occured and may have timestamps that should be in between events that have already been written out to the filesystem. One solution is to treat the exception log event as a container, and serialize the ringbuffer into the JSON representing the exception as a field with an array of logging events, but then that localizes that data to the individual event when the problem could be across multiple events and not exception specific.
Databases solve this problem: you can backfill out those diagnostic events with exactly the data and timestamps that they were created, and the database will show them as regular log events in the correct order.
Importing and Exporting
You can, of course, import data from files into the database directly, which is great if you have one service that you can't process into JSON or a database directly. You can even import CSV, or convert CSV to NDJSON and convert it that way. You can even use Foreign Data Wrappers to serve data from MongoDB or Redis.
Likewise, you can export your database in any format you want, using pretty much any tool that you want.
Summary
Logs aren't flat file entries, or even JSON: they're semi-structured data blobs. We can treat them like the data blobs they are and use the tools that are specialized for working with data blobs: a database.
Comments